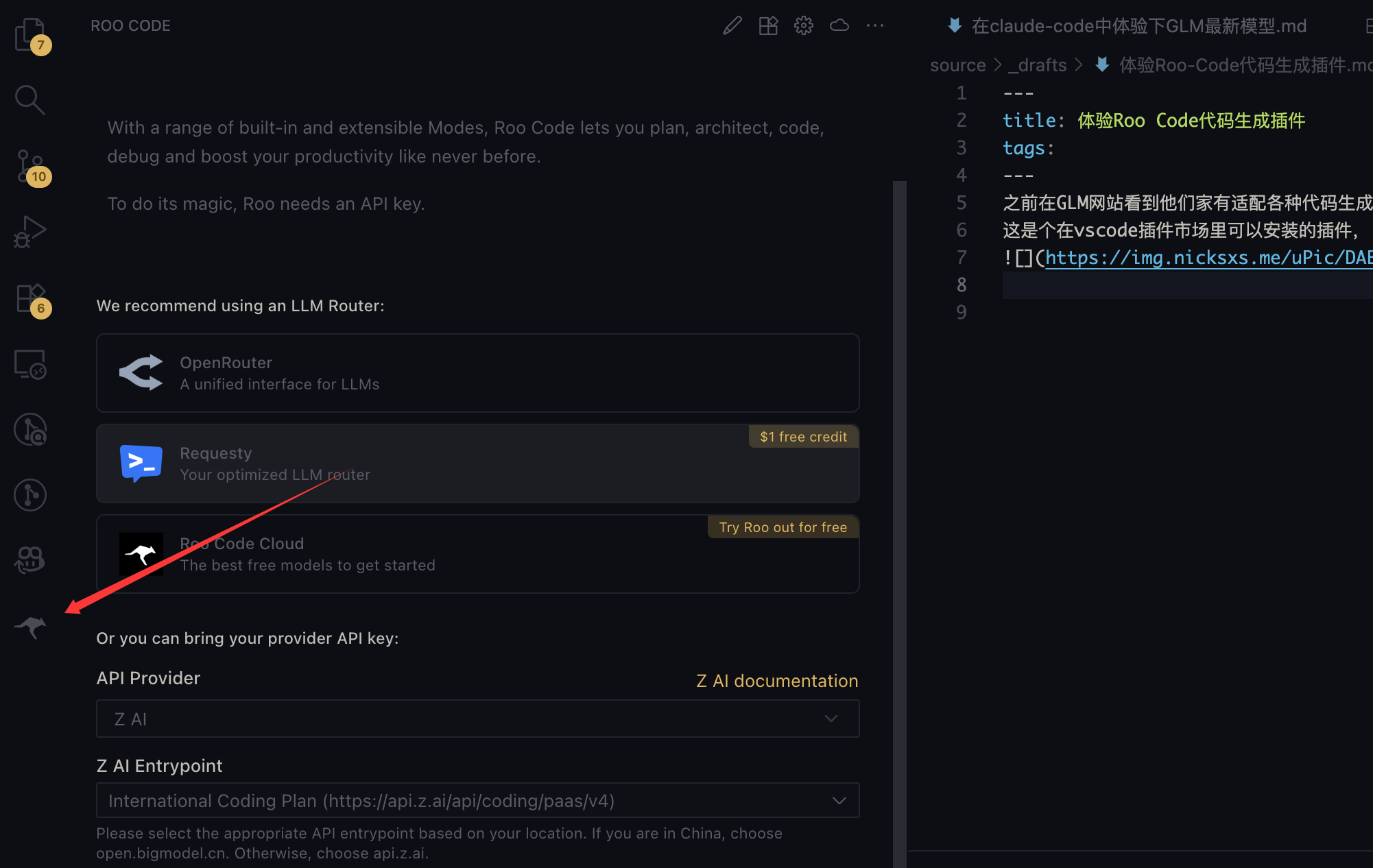
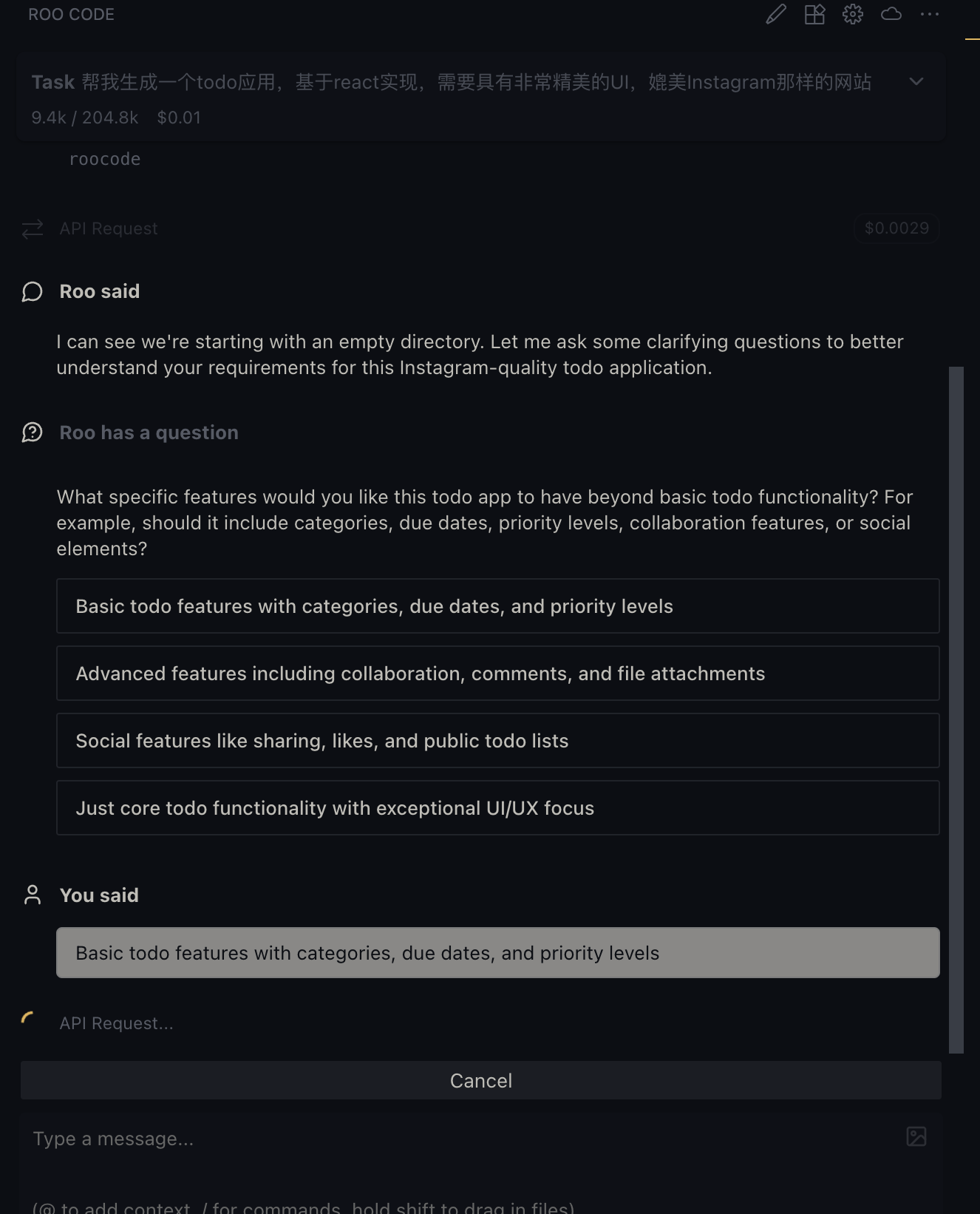
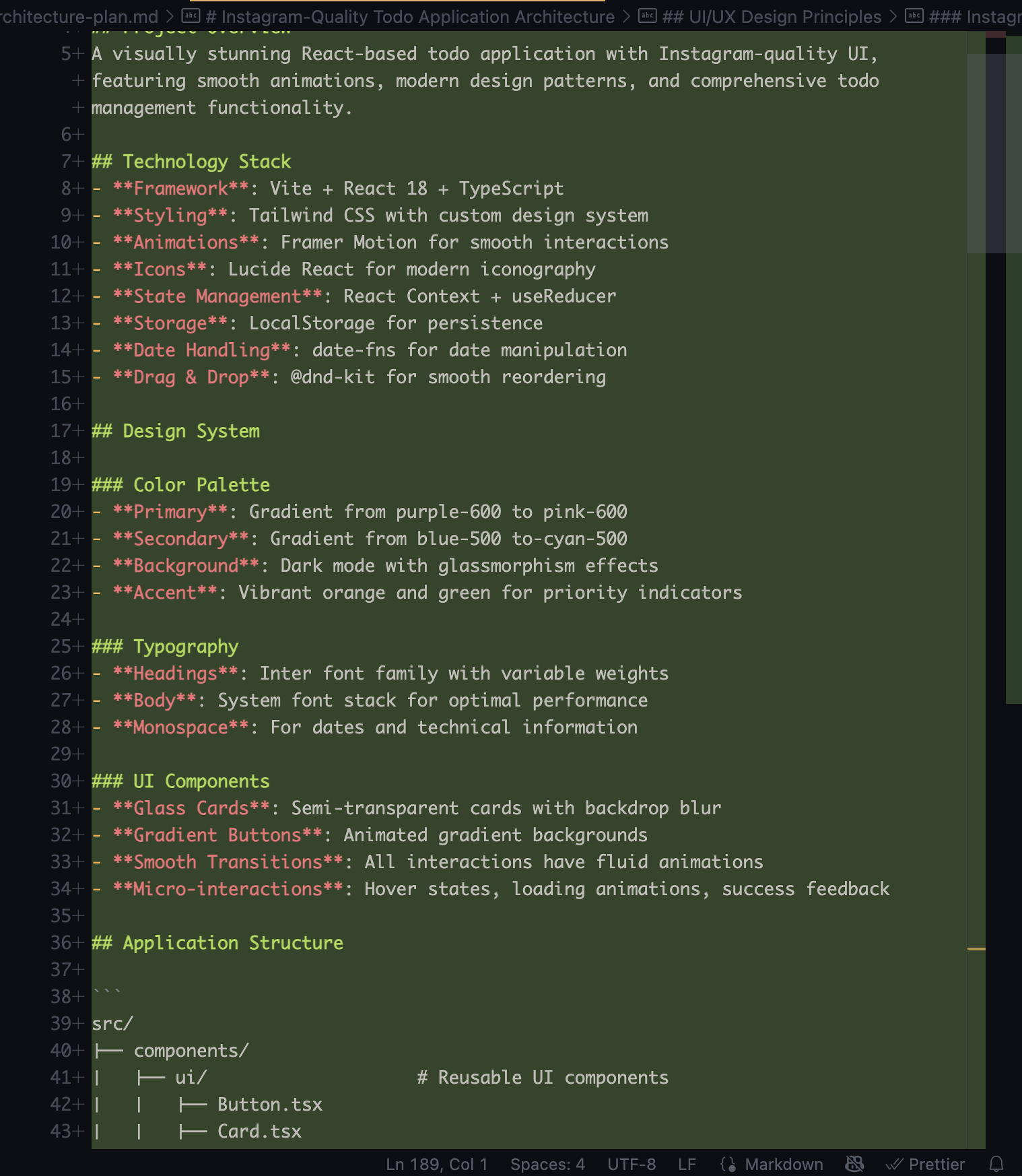
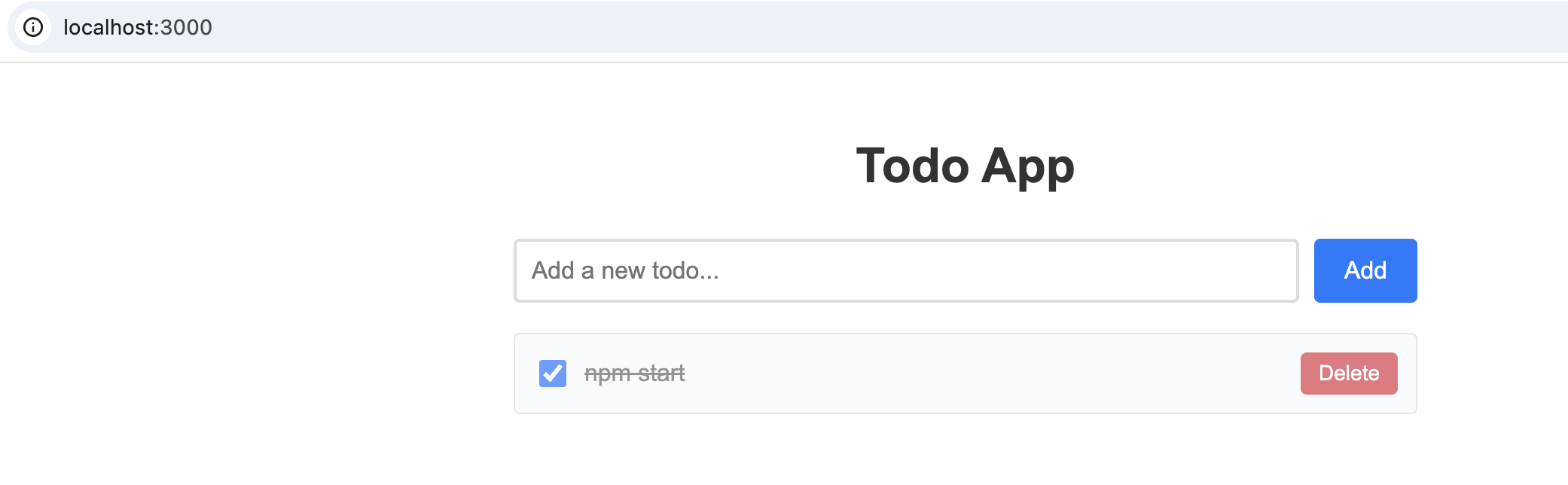
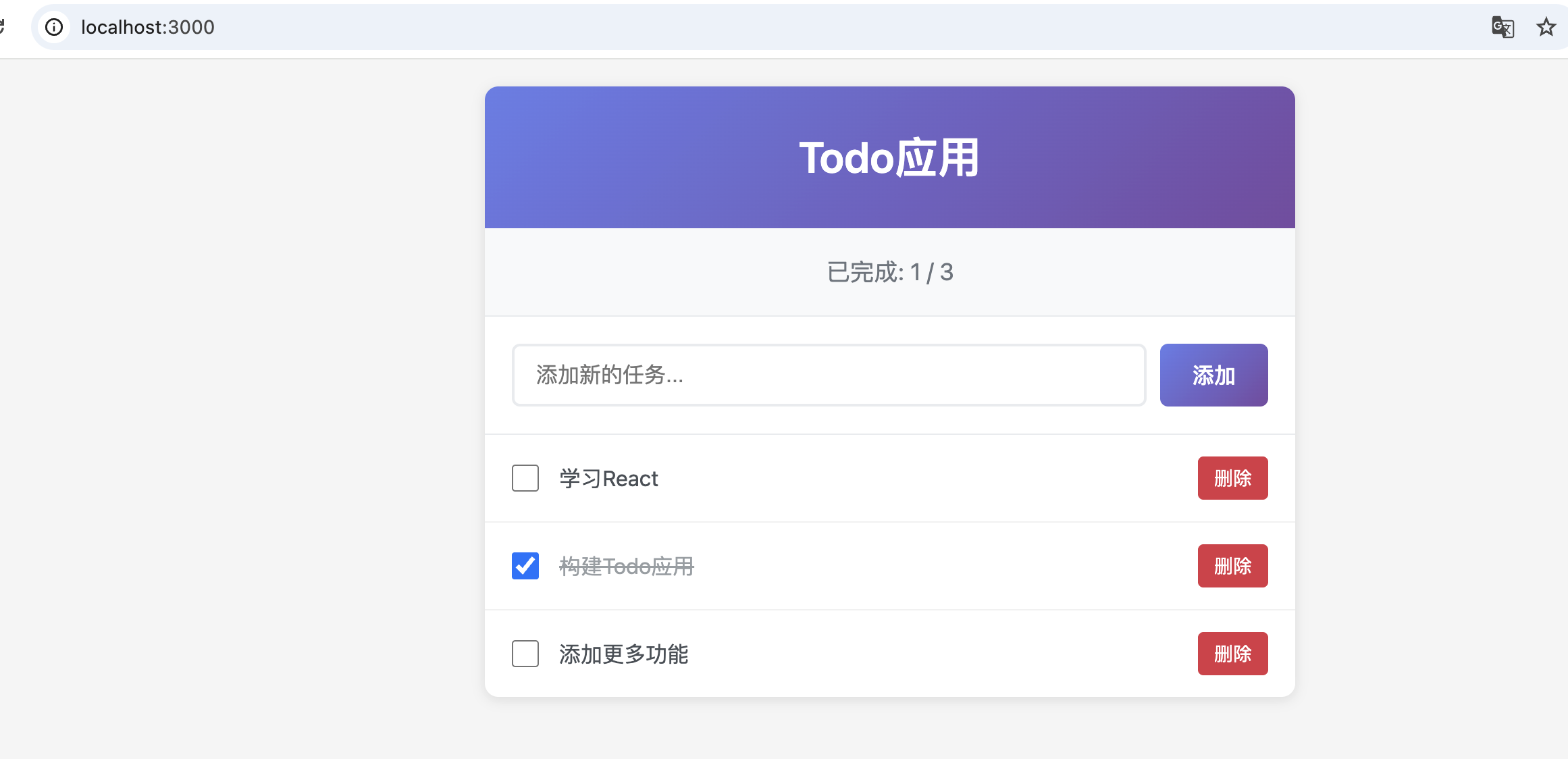
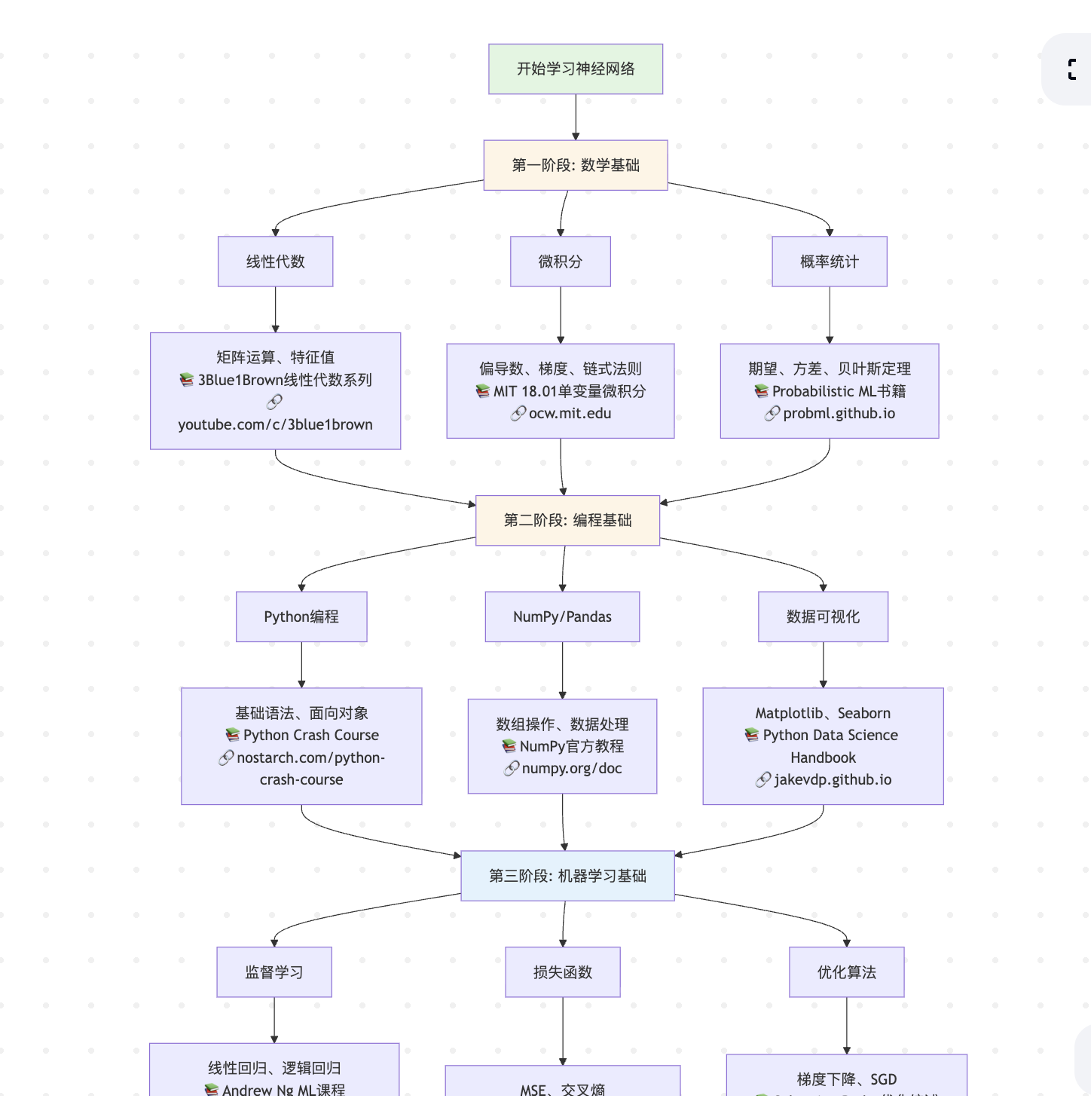
之前在GLM网站看到他们家有适配各种代码生成插件,就先来体验下这个Roo Code 这是个在vscode插件市场里可以安装的插件, 安装完在这就有个图标了 然后在API Provider里选择 Z AI Z AI Entrypoint 选择 China Coding Plan Z AI API KEY 就是他们家的API KEY 然后选择Model,可以选择最新的glm-4.6 这样就配置好了 还是以相同任务来做下测验 他会先逐个求问,来帮忙细化我前面比较粗略的prompt 然后会生成这样的架构计划 这让我觉得有点惊喜,在开发前已经在做系分和架构设计了
但是在N步之后,还是有出了问题 12:23:12 AM [vite] (client) Pre-transform error: [postcss] It looks like you're trying to usetailwindcssdirectly as a PostCSS plugin. The PostCSS plugin has moved to a separate package, so to continue using Tailwind CSS with PostCSS you'll need to install@tailwindcss/postcssand update your PostCSS configuration. Plugin: vite:css
sequenceDiagram actor User as 👤 用户 participant Web as 🌐 Web/App前端 participant Gateway as 🚪 API网关 participant Auth as 🔐 认证服务 participant Product as 📦 商品服务 participant Cart as 🛒 购物车服务 participant Order as 📋 订单服务 participant Inventory as 📊 库存服务 participant Coupon as 🎫 优惠券服务 participant Payment as 💳 支付服务 participant PayGateway as 💰 支付网关 participant MQ as 📨 消息队列 participant WMS as 🏭 仓储系统 participant Logistics as 🚚 物流系统 participant Notify as 📧 通知服务 participant AfterSale as 🔄 售后服务 participant Finance as 💵 财务系统
Note over User,Finance: 📚 参考架构:微服务电商系统<br/>🔗 github.com/macrozheng/mall
%% 登录认证阶段 rect rgb(230, 245, 255) Note over User,Auth: 第一阶段:用户认证 User->>Web: 1. 打开电商平台 Web->>Gateway: 2. 请求登录页面 Gateway->>Auth: 3. 验证会话状态 alt 未登录 Auth-->>Web: 4. 返回登录页面 User->>Web: 5. 输入账号密码/手机验证码 Web->>Auth: 6. 提交登录请求 Note right of Auth: 🔐 JWT Token生成<br/>📚 RFC 7519标准<br/>🔗 jwt.io Auth->>Auth: 7. 验证凭证 Auth-->>Web: 8. 返回Token Web->>Web: 9. 存储Token到Cookie/LocalStorage else 已登录 Auth-->>Web: 4. 验证通过 end end
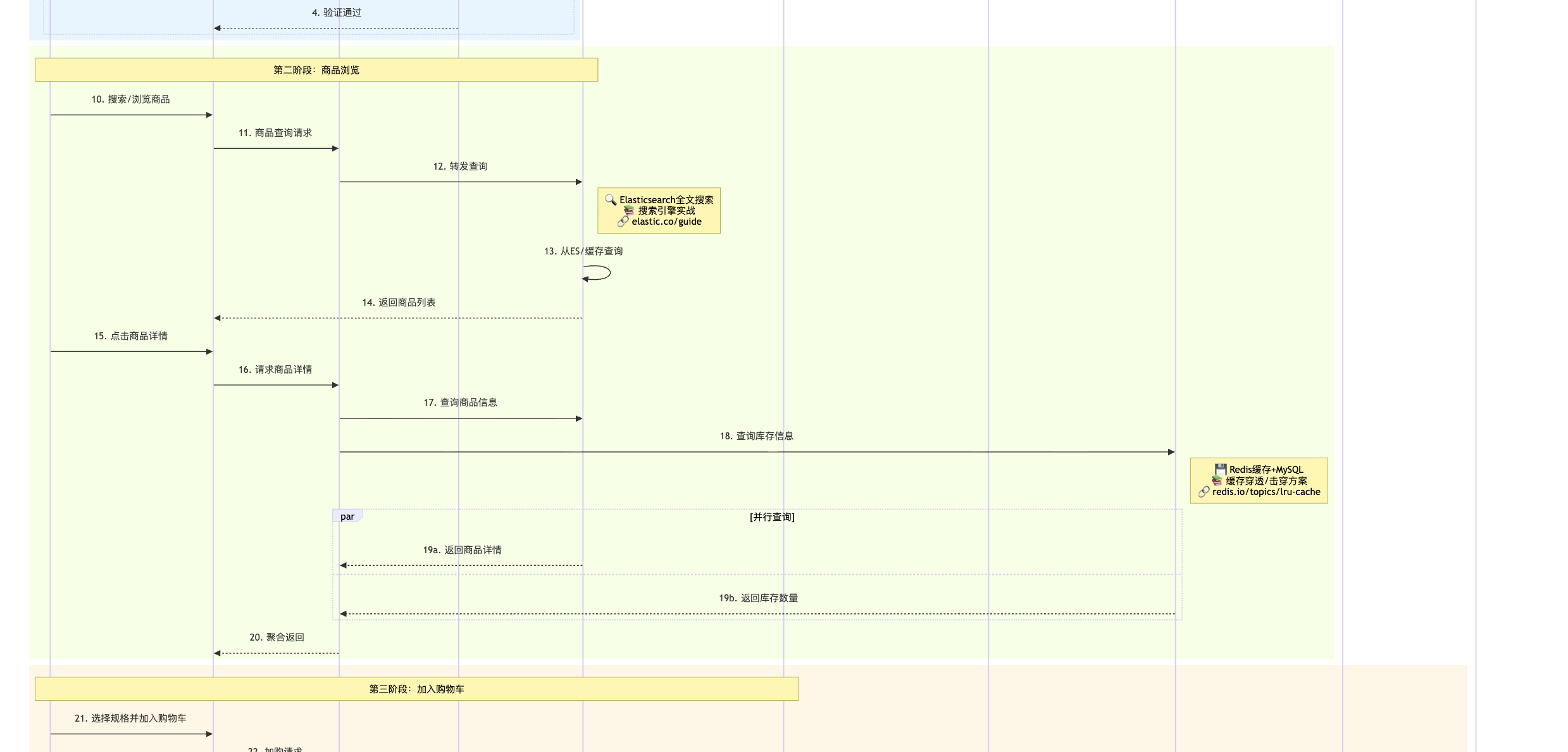
%% 商品浏览阶段 rect rgb(245, 255, 230) Note over User,Product: 第二阶段:商品浏览 User->>Web: 10. 搜索/浏览商品 Web->>Gateway: 11. 商品查询请求 Gateway->>Product: 12. 转发查询 Note right of Product: 🔍 Elasticsearch全文搜索<br/>📚 搜索引擎实战<br/>🔗 elastic.co/guide Product->>Product: 13. 从ES/缓存查询 Product-->>Web: 14. 返回商品列表 User->>Web: 15. 点击商品详情 Web->>Gateway: 16. 请求商品详情 Gateway->>Product: 17. 查询商品信息 Gateway->>Inventory: 18. 查询库存信息 Note right of Inventory: 💾 Redis缓存+MySQL<br/>📚 缓存穿透/击穿方案<br/>🔗 redis.io/topics/lru-cache par 并行查询 Product-->>Gateway: 19a. 返回商品详情 and Inventory-->>Gateway: 19b. 返回库存数量 end Gateway-->>Web: 20. 聚合返回 end
%% 购物车阶段 rect rgb(255, 245, 230) Note over User,Cart: 第三阶段:加入购物车 User->>Web: 21. 选择规格并加入购物车 Web->>Gateway: 22. 加购请求 Gateway->>Cart: 23. 添加到购物车 Note right of Cart: 🗄️ Redis存储购物车<br/>📚 分布式Session方案<br/>🔗 spring.io/projects/spring-session Cart->>Inventory: 24. 验证库存是否充足 Inventory-->>Cart: 25. 返回库存状态 Cart->>Cart: 26. 计算商品小计 Cart-->>Web: 27. 返回购物车数据 User->>Web: 28. 查看购物车 Web->>Gateway: 29. 获取购物车列表 Gateway->>Cart: 30. 查询购物车 Cart->>Product: 31. 批量查询商品最新价格 Cart->>Coupon: 32. 查询可用优惠券 Note right of Coupon: 🎫 优惠券系统设计<br/>📚 促销引擎架构<br/>🔗 tech.meituan.com par 并行查询 Product-->>Cart: 33a. 返回价格信息 and Coupon-->>Cart: 33b. 返回可用优惠券 end Cart-->>Web: 34. 返回购物车详情 end
%% 订单创建阶段 rect rgb(255, 240, 245) Note over User,Order: 第四阶段:订单创建 User->>Web: 35. 点击结算 Web->>Gateway: 36. 进入结算页 Gateway->>Order: 37. 创建预订单 User->>Web: 38. 选择收货地址/优惠券 Web->>Gateway: 39. 提交订单 Gateway->>Order: 40. 创建订单请求 Note right of Order: 🔢 雪花算法生成订单号<br/>📚 分布式ID生成方案<br/>🔗 github.com/twitter/snowflake Order->>Order: 41. 生成订单号 Order->>Coupon: 42. 锁定优惠券 Order->>Inventory: 43. 预扣减库存 Note right of Inventory: ⚠️ 分布式锁防超卖<br/>📚 Redis+Lua脚本<br/>🔗 redisson.org alt 库存充足 Inventory-->>Order: 44. 扣减成功 Coupon-->>Order: 45. 锁定成功 Order->>Order: 46. 订单状态:待支付 Order-->>Web: 47. 返回订单信息 else 库存不足 Inventory-->>Order: 44. 库存不足 Order-->>Web: 47. 返回库存不足提示 end end
%% 支付阶段 rect rgb(240, 248, 255) Note over User,PayGateway: 第五阶段:支付处理 User->>Web: 48. 选择支付方式 Web->>Gateway: 49. 发起支付请求 Gateway->>Payment: 50. 创建支付单 Note right of Payment: 💳 聚合支付设计<br/>📚 支付系统架构<br/>🔗 github.com/Exrick/xpay Payment->>Payment: 51. 生成支付单号 Payment->>Order: 52. 关联订单 Payment->>PayGateway: 53. 调用支付渠道 alt 支付宝支付 Note right of PayGateway: 💰 支付宝SDK<br/>📚 开放平台文档<br/>🔗 opendocs.alipay.com PayGateway->>PayGateway: 54. 调用支付宝API else 微信支付 Note right of PayGateway: 💚 微信支付API<br/>📚 支付开发文档<br/>🔗 pay.weixin.qq.com PayGateway->>PayGateway: 54. 调用微信支付API end PayGateway-->>User: 55. 返回支付页面/二维码 User->>User: 56. 完成支付操作 Note over PayGateway,Payment: 🔔 异步回调通知 PayGateway->>Payment: 57. 支付成功回调 Note right of Payment: 📚 幂等性设计<br/>🔗 martinfowler.com/articles/patterns-of-distributed-systems Payment->>Payment: 58. 验证签名并去重 Payment->>Order: 59. 更新订单状态为已支付 Payment->>MQ: 60. 发送支付成功消息 par 异步处理 MQ->>Notify: 61a. 发送通知 Note right of Notify: 📧 消息推送<br/>📚 RabbitMQ/Kafka<br/>🔗 rabbitmq.com Notify->>User: 短信/邮件/Push通知 and MQ->>Order: 61b. 确认订单 Order->>Order: 更新订单:待发货 end end
%% 仓储物流阶段 rect rgb(232, 245, 233) Note over Order,Logistics: 第六阶段:仓储配送 Order->>WMS: 62. 推送发货指令 Note right of WMS: 📦 WMS系统设计<br/>📚 仓储管理实践<br/>🔗 github.com/topics/wms WMS->>WMS: 63. 订单拆分(多仓) WMS->>WMS: 64. 波次拣货 WMS->>WMS: 65. 打包称重 WMS->>Logistics: 66. 创建物流订单 Note right of Logistics: 🚚 电子面单生成<br/>📚 菜鸟/快递鸟API<br/>🔗 kdniao.com Logistics->>Logistics: 67. 生成运单号 Logistics->>Logistics: 68. 打印电子面单 Logistics-->>WMS: 69. 返回物流信息 WMS->>Order: 70. 更新订单为已发货 Order->>MQ: 71. 发送发货消息 MQ->>Notify: 72. 通知用户已发货 Notify->>User: 73. 发送物流信息 loop 物流跟踪 Logistics->>Logistics: 74. 更新物流轨迹 Note right of Logistics: 🗺️ 物流轨迹追踪<br/>📚 快递100 API<br/>🔗 kuaidi100.com Logistics->>Order: 75. 同步物流状态 Order->>Notify: 76. 推送物流更新 Notify->>User: 77. 实时物流通知 end Logistics->>Order: 78. 签收成功 Order->>Order: 79. 更新订单:已签收 Order->>MQ: 80. 发送签收消息 end
%% 订单完成阶段 rect rgb(255, 243, 224) Note over User,Finance: 第七阶段:订单完成 MQ->>Order: 81. 触发自动确认收货定时器 Note right of Order: ⏰ 7天自动确认<br/>📚 XXL-Job定时任务<br/>🔗 xuxueli.com/xxl-job alt 用户主动确认 User->>Web: 82a. 确认收货 Web->>Order: 83a. 确认收货请求 else 超时自动确认 Order->>Order: 82b. 7天后自动确认 end Order->>Order: 84. 订单状态:已完成 Order->>Finance: 85. 触发结算 Note right of Finance: 💰 T+1结算<br/>📚 财务对账系统<br/>🔗 accounting-system-design.com Finance->>Finance: 86. 计算平台佣金 Finance->>Finance: 87. 生成结算单 User->>Web: 88. 评价商品 Web->>Product: 89. 提交评价 Note right of Product: ⭐ UGC内容审核<br/>📚 评价系统设计<br/>🔗 review-system-architecture.com Product->>Product: 90. 审核并发布评价 end
%% 售后阶段 rect rgb(255, 235, 238) Note over User,AfterSale: 第八阶段:售后服务(可选) opt 需要售后 User->>Web: 91. 申请退货/换货 Web->>AfterSale: 92. 创建售后单 Note right of AfterSale: 🔄 售后工单系统<br/>📚 7天无理由退货<br/>🔗 消费者权益保护法 AfterSale->>AfterSale: 93. 售后审核 alt 审核通过 AfterSale-->>User: 94. 审核通过,返回退货地址 User->>Logistics: 95. 寄回商品 Logistics->>WMS: 96. 商品入库 WMS->>AfterSale: 97. 确认收货 AfterSale->>Inventory: 98. 库存回补 AfterSale->>Payment: 99. 发起退款 Note right of Payment: 💵 原路退回<br/>📚 退款流程设计<br/>🔗 refund-process-design.com Payment->>PayGateway: 100. 调用退款接口 PayGateway-->>Payment: 101. 退款成功 Payment->>MQ: 102. 发送退款消息 MQ->>Notify: 103. 通知用户 Notify->>User: 104. 退款到账通知 else 审核拒绝 AfterSale-->>User: 94. 拒绝售后申请 end end end
%% 数据分析阶段 rect rgb(227, 242, 253) Note over Order,Finance: 第九阶段:数据统计分析 Note over Order,Finance: 📊 实时数据大屏<br/>📚 Flink流式计算<br/>🔗 flink.apache.org par 数据采集 Order->>MQ: 订单数据埋点 and Payment->>MQ: 支付数据埋点 and Product->>MQ: 商品数据埋点 end MQ->>Finance: 数据聚合分析 Finance->>Finance: 生成报表<br/>(销售额/转化率/ROI等) Note right of Finance: 📈 BI系统<br/>📚 数据仓库建设<br/>🔗 github.com/topics/data-warehouse end
<!-- The ADK Dev Web UI to debug your agent (Optional) --> <dependency> <groupId>com.google.adk</groupId> <artifactId>google-adk-dev</artifactId> <version>0.2.0</version> </dependency> </dependencies>
// The run your agent with Dev UI, the ROOT_AGENT should be a global public static final variable. publicstaticfinalBaseAgentROOT_AGENT= initAgent();
publicstatic BaseAgent initAgent() { return LlmAgent.builder() .name(NAME) .model("gemini-2.0-flash") .description("Agent to answer questions about the time and weather in a city.") .instruction( "You are a helpful agent who can answer user questions about the time and weather" + " in a city.") .tools( FunctionTool.create(MultiToolAgent.class, "getCurrentTime"), FunctionTool.create(MultiToolAgent.class, "getWeather")) .build(); }
publicstatic Map<String, String> getCurrentTime( @Schema(name = "city", description = "The name of the city for which to retrieve the current time") String city) { StringnormalizedCity= Normalizer.normalize(city, Normalizer.Form.NFD) .trim() .toLowerCase() .replaceAll("(\\p{IsM}+|\\p{IsP}+)", "") .replaceAll("\\s+", "_");
return ZoneId.getAvailableZoneIds().stream() .filter(zid -> zid.toLowerCase().endsWith("/" + normalizedCity)) .findFirst() .map( zid -> Map.of( "status", "success", "report", "The current time in " + city + " is " + ZonedDateTime.now(ZoneId.of(zid)) .format(DateTimeFormatter.ofPattern("HH:mm")) + ".")) .orElse( Map.of( "status", "error", "report", "Sorry, I don't have timezone information for " + city + ".")); }
publicstatic Map<String, String> getWeather( @Schema(name = "city", description = "The name of the city for which to retrieve the weather report") String city) { if (city.toLowerCase().equals("new york")) { return Map.of( "status", "success", "report", "The weather in New York is sunny with a temperature of 25 degrees Celsius (77 degrees" + " Fahrenheit).");
} else { return Map.of( "status", "error", "report", "Weather information for " + city + " is not available."); } }