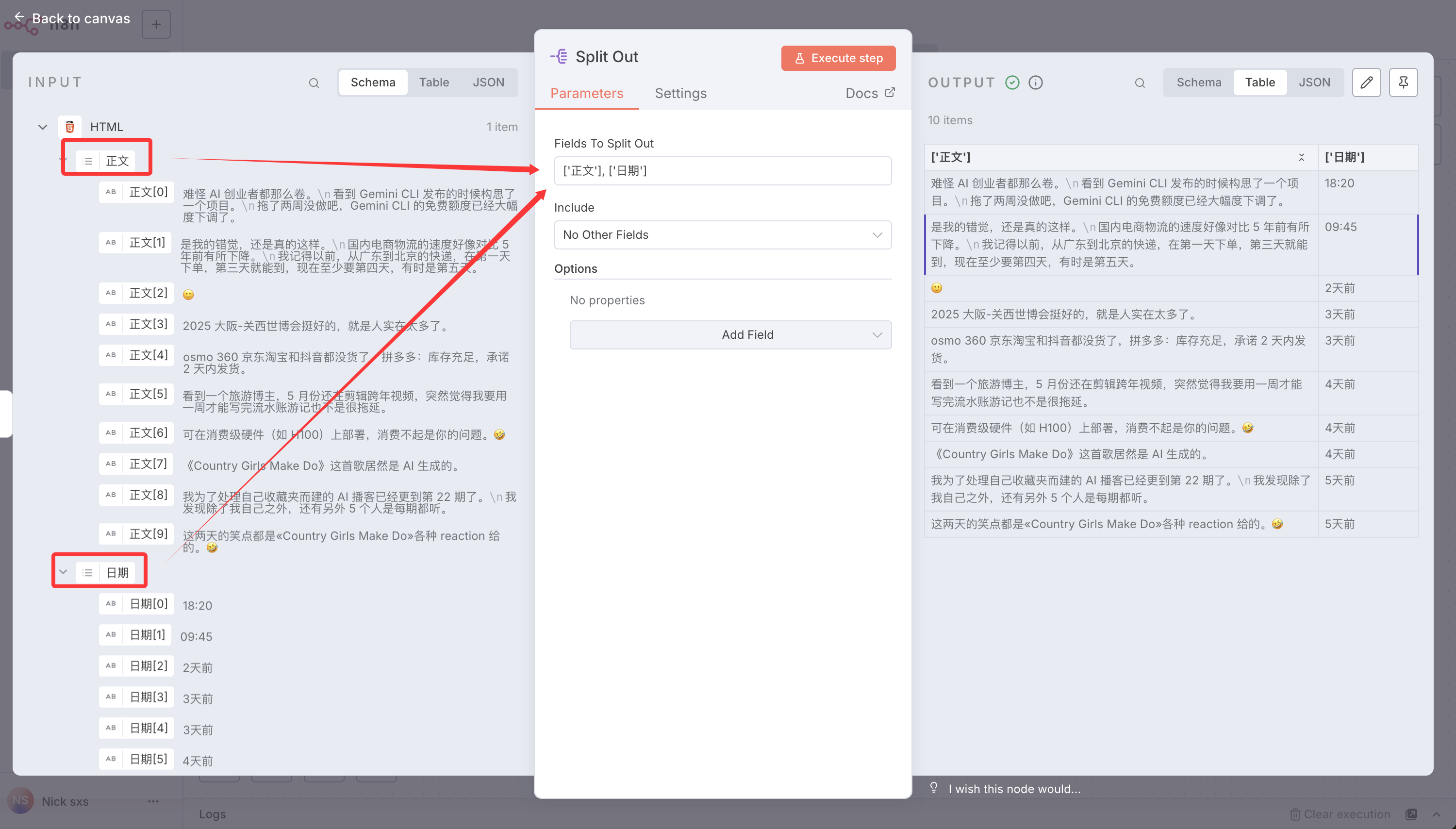
SELECT ta.* FROM students ta JOIN ( SELECT class, MAX(age) as max_age FROM students GROUPBY class ) as tb ON ta.class = tb.class AND ta.age = tb.max_age;
分析:
子查询阶段:SELECT class, MAX(age) as max_age FROM students GROUP BY class
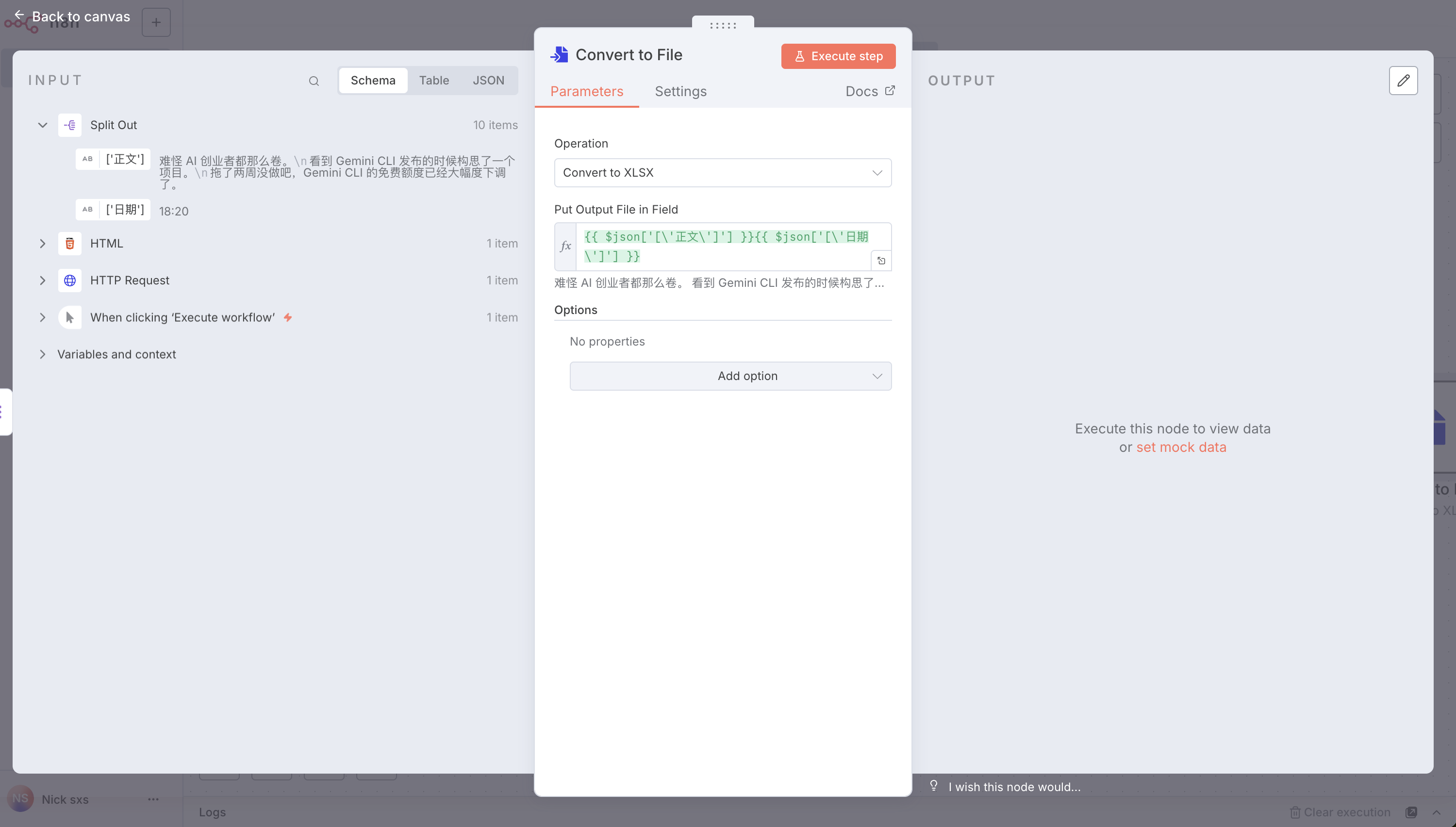
SELECT*FROM ( SELECT*, ROW_NUMBER() OVER (PARTITIONBY class ORDERBY age DESC) as row_num FROM students ) t WHERE row_num =1;
核心概念解析:
PARTITION BY class:按班级进行分区
可以理解为逻辑上的分组,但不会像GROUP BY那样聚合数据
每个分区内部可以独立进行排序和编号
ORDER BY age DESC:在每个分区内按年龄降序排序
年龄最大的学生排在第一位
**ROW_NUMBER()**:为每个分区内的行分配唯一序号
从1开始递增,即使有相同值也会分配不同序号
这就解决了传统方法中重复值的问题
外层WHERE row_num = 1:筛选每个分区的第一条记录
其他窗口函数选择
除了ROW_NUMBER(),还可以根据业务需求选择其他窗口函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
-- 使用RANK():相同值会有相同排名,但会跳跃序号 SELECT*FROM ( SELECT*, RANK() OVER (PARTITIONBY class ORDERBY age DESC) as rank_num FROM students ) t WHERE rank_num =1;
-- 使用DENSE_RANK():相同值有相同排名,但不跳跃序号 SELECT*FROM ( SELECT*, DENSE_RANK() OVER (PARTITIONBY class ORDERBY age DESC) as dense_rank_num FROM students ) t WHERE dense_rank_num =1;
性能对比与优势
窗口函数的优势:
代码简洁性:逻辑更直观,维护成本更低
性能优化:只需一次表扫描,避免了JOIN操作
功能丰富:提供多种排名函数应对不同场景
处理重复值:ROW_NUMBER()确保每个分组只返回一条记录
适用场景扩展:
Top-N查询:每个分组的前N条记录
数据去重:基于特定字段的去重逻辑
百分位计算:使用PERCENT_RANK()等函数
移动平均:结合ROWS BETWEEN进行滑动窗口计算
MySQL 8.0的窗口函数为分组排序查询提供了更现代化的解决方案。相比传统的子查询+JOIN方式,窗口函数不仅在语法上更加简洁直观,在性能上也有显著提升。对于需要在分组内进行复杂数据分析的场景,窗口函数已经成为不可或缺的利器。