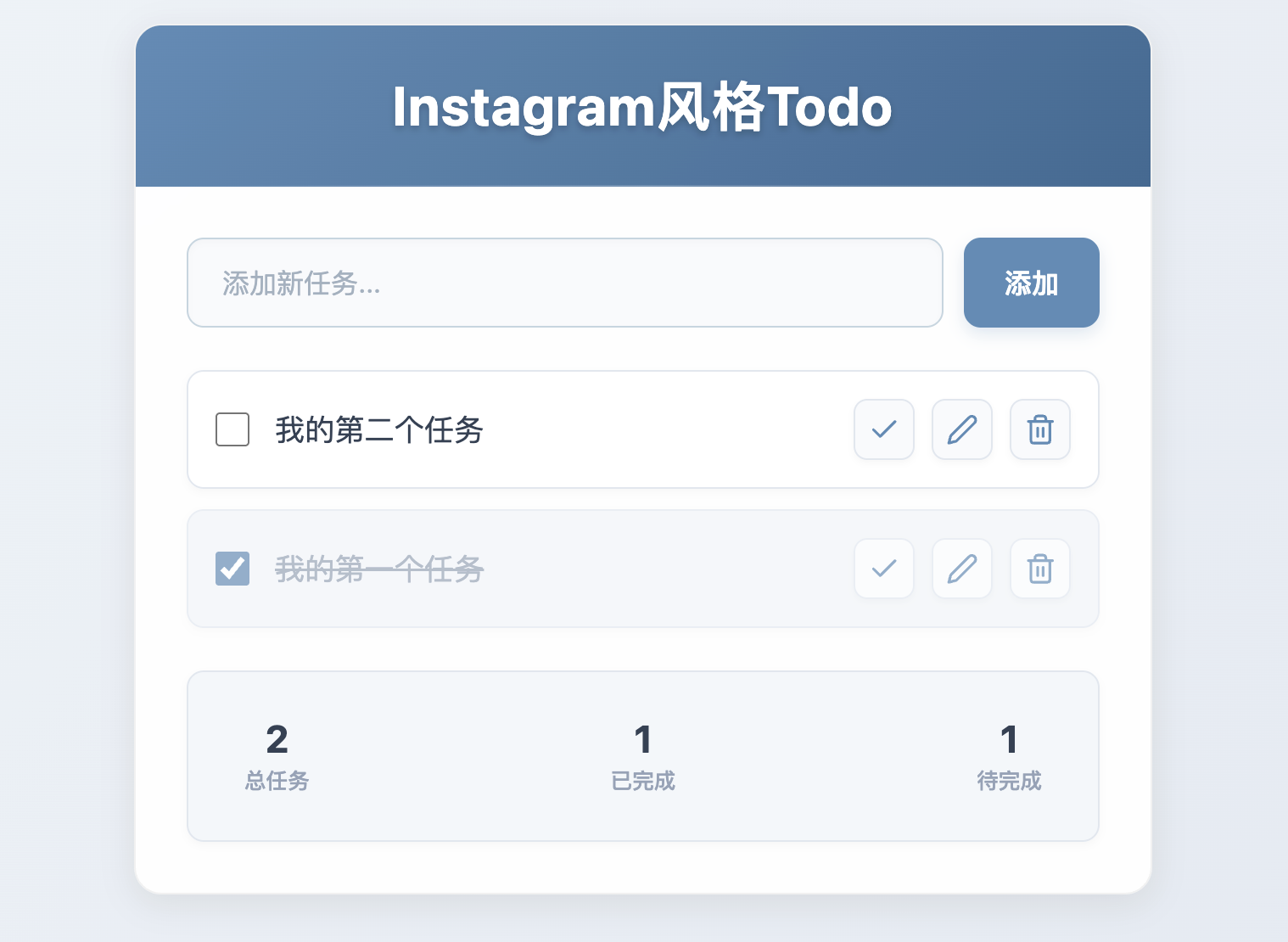
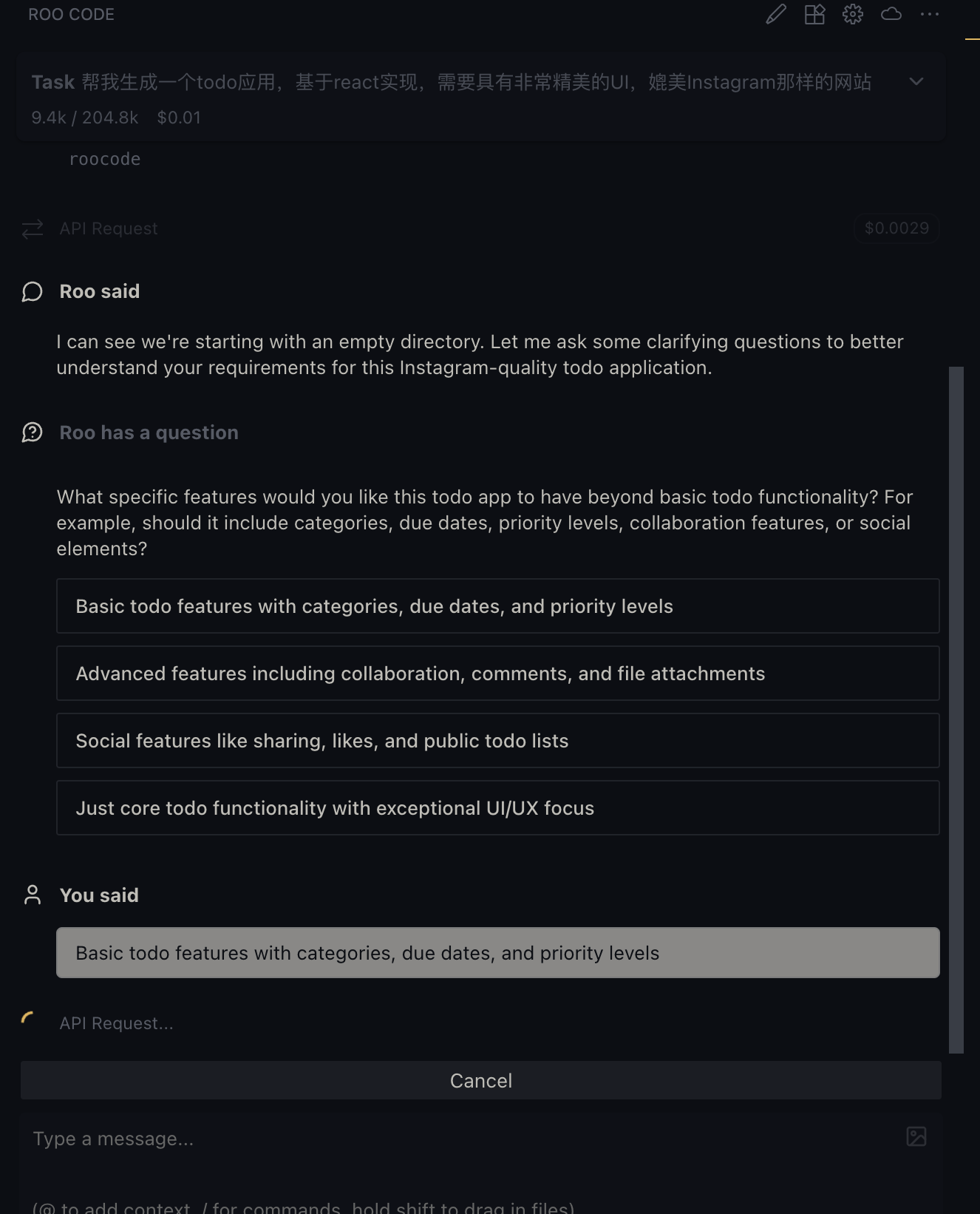
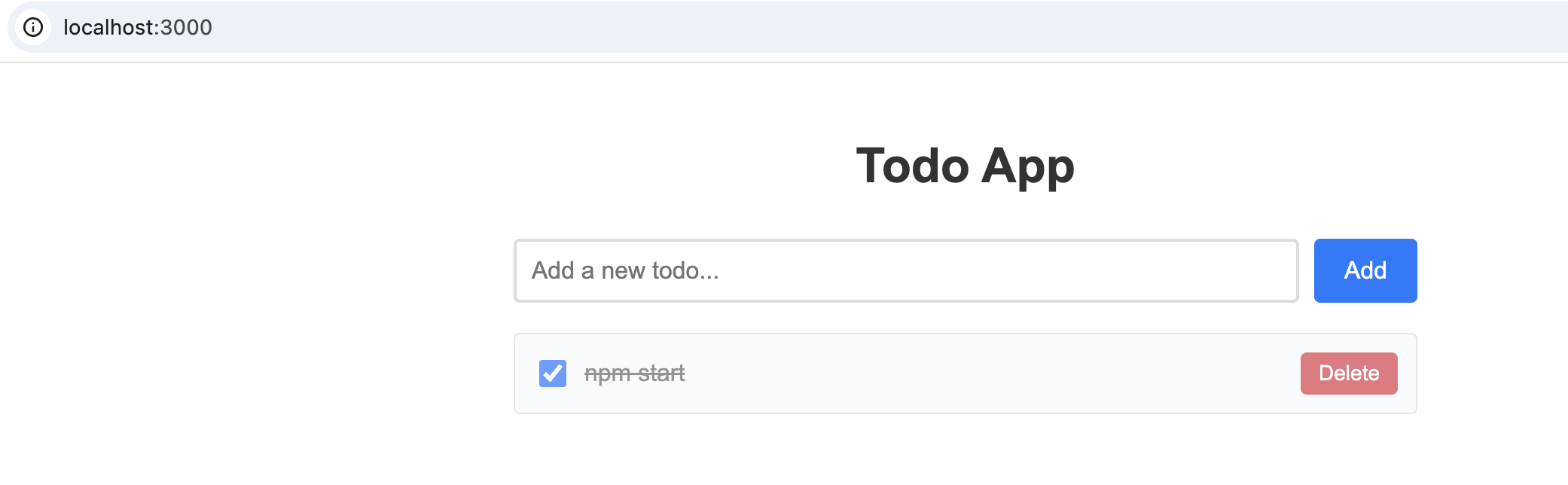
基于iflow的kimi模型来体验代码生成
首先是生成plan
完整生成完后还是无法运行,多次把问题提给kimi也没有解决1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60Compiled with warnings.
[eslint]
src/components/TodoItem.tsx
Line 4:19: 'FiX' is defined but never used @typescript-eslint/no-unused-vars
Line 4:108: 'FiClock' is defined but never used @typescript-eslint/no-unused-vars
Line 213:7: 'ActionBar' is assigned a value but never used @typescript-eslint/no-unused-vars
Line 222:7: 'ActionButtons' is assigned a value but never used @typescript-eslint/no-unused-vars
Line 334:7: 'Timestamp' is assigned a value but never used @typescript-eslint/no-unused-vars
Search for the keywords to learn more about each warning.
To ignore, add // eslint-disable-next-line to the line before.
WARNING in [eslint]
src/components/TodoItem.tsx
Line 4:19: 'FiX' is defined but never used @typescript-eslint/no-unused-vars
Line 4:108: 'FiClock' is defined but never used @typescript-eslint/no-unused-vars
Line 213:7: 'ActionBar' is assigned a value but never used @typescript-eslint/no-unused-vars
Line 222:7: 'ActionButtons' is assigned a value but never used @typescript-eslint/no-unused-vars
Line 334:7: 'Timestamp' is assigned a value but never used @typescript-eslint/no-unused-vars
webpack compiled with 1 warning
Files successfully emitted, waiting for typecheck results...
Issues checking in progress...
ERROR in src/components/Header.tsx:270:16
TS2786: 'FiSearch' cannot be used as a JSX component.
Its return type 'ReactNode' is not a valid JSX element.
Type 'undefined' is not assignable to type 'Element | null'.
268 | <SearchContainer>
269 | <SearchIcon>
> 270 | <FiSearch {...({ size: 16 } as any)} />
| ^^^^^^^^
271 | </SearchIcon>
272 | <SearchInput
273 | type="text"
ERROR in src/components/Header.tsx:300:18
TS2786: 'FiHome' cannot be used as a JSX component.
Its return type 'ReactNode' is not a valid JSX element.
298 | <NavIcons>
299 | <NavIcon>
> 300 | <FiHome {...({ size: 24 } as any)} />
| ^^^^^^
301 | </NavIcon>
302 | <NavIcon>
303 | <FiCompass {...({ size: 24 } as any)} />
ERROR in src/components/TodoItem.tsx:453:43
TS2786: 'FiTag' cannot be used as a JSX component.
Its return type 'ReactNode' is not a valid JSX element.
451 | {todo.priority === 'high' ? '🔴 高' : todo.priority === 'medium' ? '🟡 中' : '🟢 低'}
452 | </PriorityBadge>
> 453 | {todo.category && <CategoryTag><FiTag size={10} /> #{todo.category}</CategoryTag>}
| ^^^^^
454 |
455 | <div style={{ position: 'relative' }}>
456 | <MoreButton onClick={() => setShowDropdown(!showDropdown)}>
没办法,后面我好好思考了下,前面因为响应一直很慢,我退出了几次又继续使用同一个prompt,但是实际的模型是需要读取原先写到一半的代码,这样其实每次的生成上下文就被搞混乱了,所以重新清理了代码,再给kimi一次机会,这次就慢慢等了
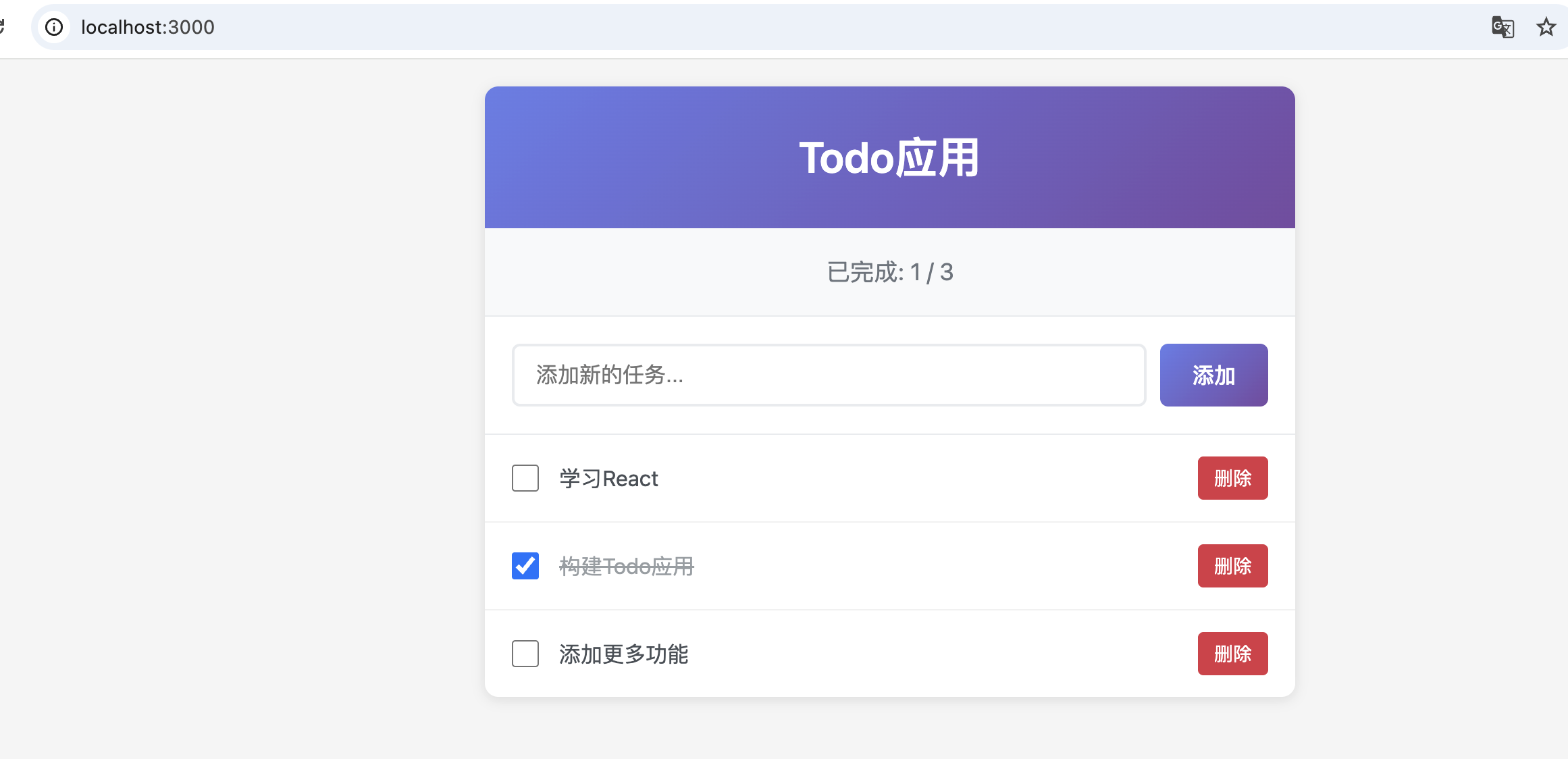
首先也是列出了todo list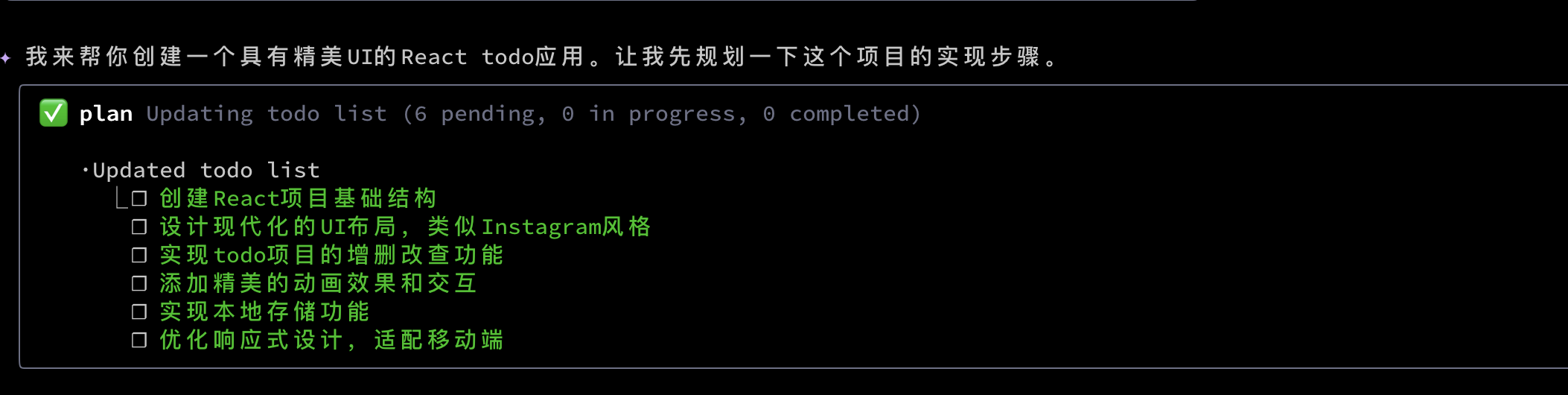
完成后主体的代码也不多1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269import React, { useState, useEffect } from 'react';
import styled from '@emotion/styled';
import { motion, AnimatePresence } from 'framer-motion';
import { Plus } from 'lucide-react';
import TodoItem from './TodoItem';
import TodoForm from './TodoForm';
export interface Todo {
id: string;
text: string;
completed: boolean;
createdAt: Date;
priority: 'low' | 'medium' | 'high';
}
const Container = styled(motion.div)`
background: rgba(255, 255, 255, 0.95);
backdrop-filter: blur(20px);
border-radius: 24px;
box-shadow: 0 25px 50px -12px rgba(0, 0, 0, 0.25);
width: 100%;
max-width: 500px;
min-height: 600px;
padding: 30px;
position: relative;
overflow: hidden;
`;
const Header = styled.div`
text-align: center;
margin-bottom: 30px;
`;
const Title = styled.h1`
font-size: 2.5rem;
font-weight: 700;
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
background-clip: text;
margin: 0;
letter-spacing: -0.02em;
`;
const Subtitle = styled.p`
color: #6b7280;
font-size: 1rem;
margin: 8px 0 0 0;
font-weight: 500;
`;
const TodoList = styled.div`
margin-top: 30px;
max-height: 400px;
overflow-y: auto;
padding-right: 10px;
&::-webkit-scrollbar {
width: 6px;
}
&::-webkit-scrollbar-track {
background: #f1f5f9;
border-radius: 3px;
}
&::-webkit-scrollbar-thumb {
background: #cbd5e1;
border-radius: 3px;
}
&::-webkit-scrollbar-thumb:hover {
background: #94a3b8;
}
`;
const EmptyState = styled(motion.div)`
text-align: center;
padding: 60px 20px;
color: #9ca3af;
`;
const EmptyIcon = styled.div`
font-size: 4rem;
margin-bottom: 16px;
opacity: 0.5;
`;
const EmptyText = styled.p`
font-size: 1.1rem;
margin: 0;
font-weight: 500;
`;
const Stats = styled.div`
display: flex;
justify-content: space-between;
align-items: center;
margin-top: 20px;
padding-top: 20px;
border-top: 1px solid #e5e7eb;
`;
const StatItem = styled.div`
text-align: center;
`;
const StatNumber = styled.div`
font-size: 1.5rem;
font-weight: 700;
color: #667eea;
`;
const StatLabel = styled.div`
font-size: 0.875rem;
color: #6b7280;
margin-top: 4px;
`;
const TodoApp: React.FC = () => {
const [todos, setTodos] = useState<Todo[]>([]);
const [showForm, setShowForm] = useState(false);
const [editingTodo, setEditingTodo] = useState<Todo | null>(null);
useEffect(() => {
const savedTodos = localStorage.getItem('todos');
if (savedTodos) {
setTodos(JSON.parse(savedTodos).map((todo: any) => ({
...todo,
createdAt: new Date(todo.createdAt)
})));
}
}, []);
useEffect(() => {
localStorage.setItem('todos', JSON.stringify(todos));
}, [todos]);
const addTodo = (text: string, priority: 'low' | 'medium' | 'high') => {
const newTodo: Todo = {
id: Date.now().toString(),
text,
completed: false,
createdAt: new Date(),
priority
};
setTodos([newTodo, ...todos]);
setShowForm(false);
};
const toggleTodo = (id: string) => {
setTodos(todos.map(todo =>
todo.id === id ? { ...todo, completed: !todo.completed } : todo
));
};
const deleteTodo = (id: string) => {
setTodos(todos.filter(todo => todo.id !== id));
};
const editTodo = (id: string, newText: string, newPriority: 'low' | 'medium' | 'high') => {
setTodos(todos.map(todo =>
todo.id === id ? { ...todo, text: newText, priority: newPriority } : todo
));
setEditingTodo(null);
};
const completedCount = todos.filter(todo => todo.completed).length;
const totalCount = todos.length;
return (
<Container
initial={{ opacity: 0, y: 20 }}
animate={{ opacity: 1, y: 0 }}
transition={{ duration: 0.6, ease: "easeOut" }}
>
<Header>
<Title>My Tasks</Title>
<Subtitle>Stay organized and productive</Subtitle>
</Header>
{showForm && (
<TodoForm
onSubmit={addTodo}
onCancel={() => setShowForm(false)}
/>
)}
{editingTodo && (
<TodoForm
todo={editingTodo}
onSubmit={(text, priority) => editTodo(editingTodo.id, text, priority)}
onCancel={() => setEditingTodo(null)}
/>
)}
<TodoList>
<AnimatePresence>
{todos.length === 0 ? (
<EmptyState
initial={{ opacity: 0 }}
animate={{ opacity: 1 }}
exit={{ opacity: 0 }}
>
<EmptyIcon>📝</EmptyIcon>
<EmptyText>No tasks yet. Add one to get started!</EmptyText>
</EmptyState>
) : (
todos.map((todo) => (
<TodoItem
key={todo.id}
todo={todo}
onToggle={toggleTodo}
onDelete={deleteTodo}
onEdit={setEditingTodo}
/>
))
)}
</AnimatePresence>
</TodoList>
{todos.length > 0 && (
<Stats>
<StatItem>
<StatNumber>{totalCount}</StatNumber>
<StatLabel>Total</StatLabel>
</StatItem>
<StatItem>
<StatNumber>{completedCount}</StatNumber>
<StatLabel>Completed</StatLabel>
</StatItem>
<StatItem>
<StatNumber>{totalCount - completedCount}</StatNumber>
<StatLabel>Remaining</StatLabel>
</StatItem>
</Stats>
)}
{!showForm && !editingTodo && (
<motion.button
style={{
position: 'absolute',
bottom: '30px',
right: '30px',
width: '60px',
height: '60px',
borderRadius: '50%',
background: 'linear-gradient(135deg, #667eea 0%, #764ba2 100%)',
border: 'none',
color: 'white',
fontSize: '24px',
cursor: 'pointer',
boxShadow: '0 10px 25px rgba(102, 126, 234, 0.4)',
display: 'flex',
alignItems: 'center',
justifyContent: 'center'
}}
whileHover={{ scale: 1.1 }}
whileTap={{ scale: 0.95 }}
onClick={() => setShowForm(true)}
>
<Plus size={24} />
</motion.button>
)}
</Container>
);
};
export default TodoApp;
一开始运行出现了个问题,新增的时候报错 Component selectors can only be used in conjunction with @emotion/babel-plugin, the swc Emotion plugin, or another Emotion-aware compiler transform.
就继续让kimi来解决这个问题,结果一次就改好了,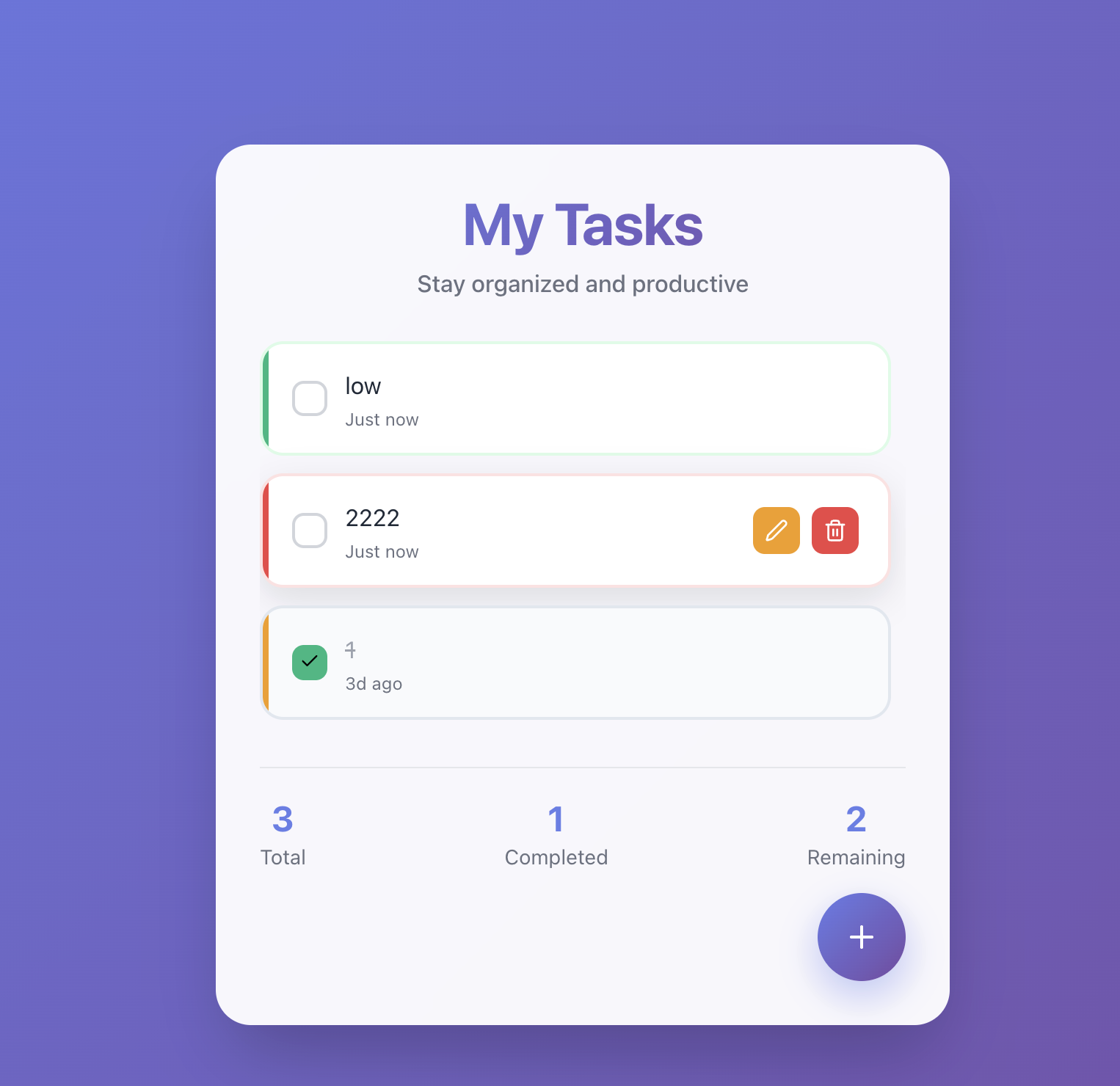
整体看起来也还行,可能的确是我一开始中断了几次导致上下文太复杂,只是不确定是模型消耗资源比较多还是什么原因响应有时候会很慢,可能免费的资源池是共用的,高峰期就比较慢了