Leetcode 124 二叉树中的最大路径和(Binary Tree Maximum Path Sum) 题解分析
题目介绍
A path in a binary tree is a sequence of nodes where each pair of adjacent nodes in the sequence has an edge connecting them. A node can only appear in the sequence at most once. Note that the path does not need to pass through the root.
The path sum of a path is the sum of the node’s values in the path.
Given the root of a binary tree, return the maximum path sum of any path.
路径 被定义为一条从树中任意节点出发,沿父节点-子节点连接,达到任意节点的序列。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和
简要分析
其实这个题目会被误解成比较简单,左子树最大的,或者右子树最大的,或者两边加一下,仔细想想都不对,其实有可能是产生于左子树中,或者右子树中,这两个都是指跟左子树根还有右子树根没关系的,这么说感觉不太容易理解,画个图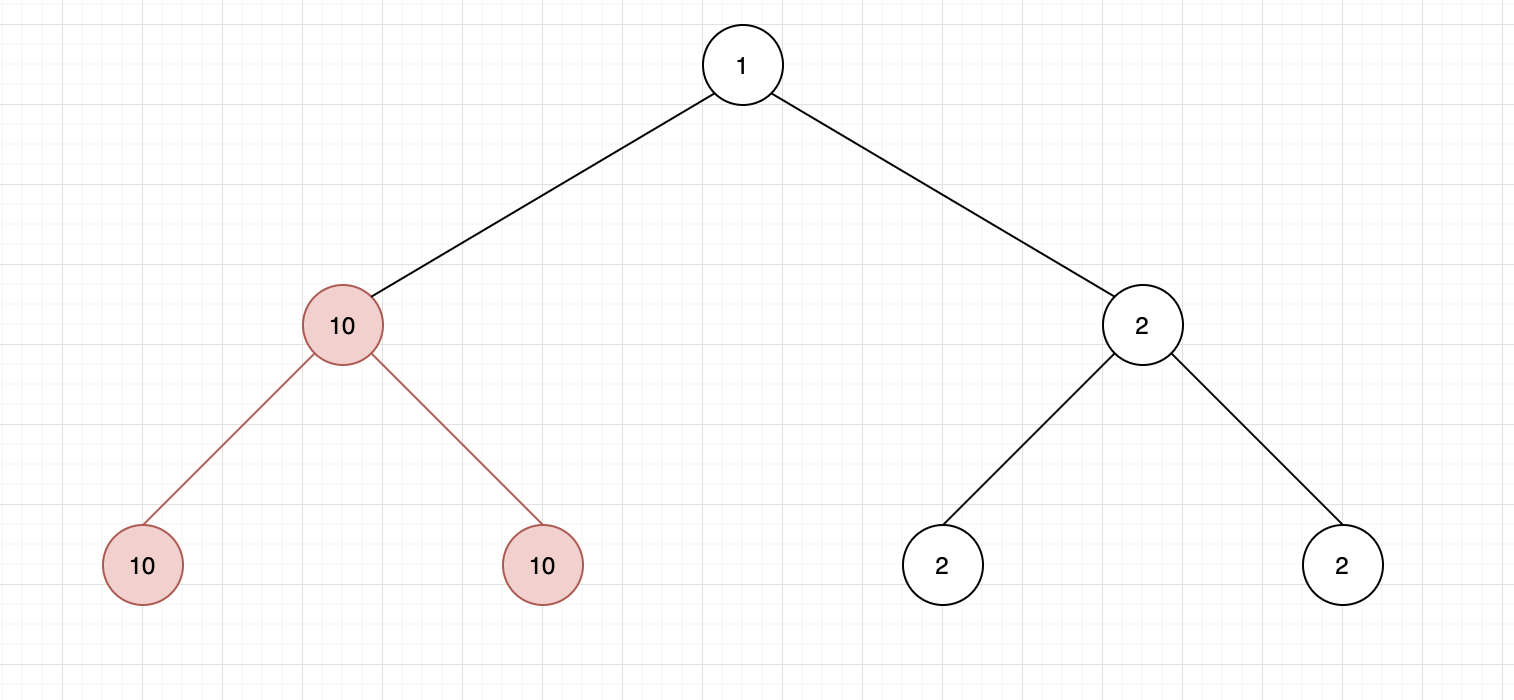
可以看到图里,其实最长路径和是左边这个子树组成的,跟根节点还有右子树完全没关系,然后再想一种情况,如果是整棵树就是图中的左子树,那么这个最长路径和就是左子树加右子树加根节点了,所以不是我一开始想得那么简单,在代码实现中也需要一些技巧
代码
1 | int ansNew = Integer.MIN_VALUE; |
这里非常重要的就是 ansNew 是最后的一个结果,而对于 maxSumNew 这个函数的返回值其实是需要包含了一个连续结果,因为要返回继续去算路径和,所以返回的是 currentSum,最终结果是 ansNew
结果图
难得有个 100%,贴个图哈哈