作为一个 Windows 的老用户,并且也算是 Windows 系统的半个粉丝,但是秉承一贯的优缺点都应该说的原则,Windows 系统有一点缺点是真的挺难受,相信 Windows 用过比较久的都会经历过,就是 U盘无法退出的问题,在比较远古时代,这个问题似乎能采取的措施不多,关机再拔 U盘的方式是一种比较保险的方式,其他貌似有 360这种可以解除占用的,但是需要安装 360 软件,对于目前的使用环境来说有点得不偿失,也是比较流氓的一类软件了,目前在 Windows 环境我主要就安装了个火绒,或者就用 Windows 自带的 defender。
第二种方式是 Windows 任务管理器中性能 tab 下的”打开资源监视器”, ,假如我的 U 盘的盘符是F: 就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。 对于前两种方式对我来说都无效,
第三种
所以尝试了第三种, 就是磁盘脱机的方式,在”计算机”右键管理,点击”磁盘管理”,可以找到 U 盘盘符右键,点击”脱机”,然后再”推出”,这个对我来说也不行
第四种
这种是唯一对我有效的,在开始菜单搜索”event”,可以搜到”事件查看器”, ,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息 最后发现是英特尔的驱动管理程序的一个进程,关掉就退出了,虽然前面说的某里的进程是流氓,但这边是真的冤枉它了
Error initializing error="failed to read or create private key: failed to save private key to disk: open /etc/headscale/private.key: read-only file system"
--- # headscale will look for a configuration file named `config.yaml` (or `config.json`) in the following order: # # - `/etc/headscale` # - `~/.headscale` # - current working directory
# The url clients will connect to. # Typically this will be a domain like: # # https://myheadscale.example.com:443 # server_url:http://127.0.0.1:8080
# Address to listen to / bind to on the server # # For production: # listen_addr: 0.0.0.0:8080 listen_addr:127.0.0.1:8080
# Address to listen to /metrics, you may want # to keep this endpoint private to your internal # network # metrics_listen_addr:127.0.0.1:9090
# Address to listen for gRPC. # gRPC is used for controlling a headscale server # remotely with the CLI # Note: Remote access _only_ works if you have # valid certificates. # # For production: # grpc_listen_addr: 0.0.0.0:50443 grpc_listen_addr:127.0.0.1:50443
# Allow the gRPC admin interface to run in INSECURE # mode. This is not recommended as the traffic will # be unencrypted. Only enable if you know what you # are doing. grpc_allow_insecure:false
# Private key used to encrypt the traffic between headscale # and Tailscale clients. # The private key file will be autogenerated if it's missing. # # For production: # /var/lib/headscale/private.key private_key_path:./private.key
# The Noise section includes specific configuration for the # TS2021 Noise protocol noise: # The Noise private key is used to encrypt the # traffic between headscale and Tailscale clients when # using the new Noise-based protocol. It must be different # from the legacy private key. # # For production: # private_key_path: /var/lib/headscale/noise_private.key private_key_path:./noise_private.key
# List of IP prefixes to allocate tailaddresses from. # Each prefix consists of either an IPv4 or IPv6 address, # and the associated prefix length, delimited by a slash. # While this looks like it can take arbitrary values, it # needs to be within IP ranges supported by the Tailscale # client. # IPv6: https://github.com/tailscale/tailscale/blob/22ebb25e833264f58d7c3f534a8b166894a89536/net/tsaddr/tsaddr.go#LL81C52-L81C71 # IPv4: https://github.com/tailscale/tailscale/blob/22ebb25e833264f58d7c3f534a8b166894a89536/net/tsaddr/tsaddr.go#L33 ip_prefixes: -fd7a:115c:a1e0::/48 -100.64.0.0/10
# DERP is a relay system that Tailscale uses when a direct # connection cannot be established. # https://tailscale.com/blog/how-tailscale-works/#encrypted-tcp-relays-derp # # headscale needs a list of DERP servers that can be presented # to the clients. derp: server: # If enabled, runs the embedded DERP server and merges it into the rest of the DERP config # The Headscale server_url defined above MUST be using https, DERP requires TLS to be in place enabled:false
# Region ID to use for the embedded DERP server. # The local DERP prevails if the region ID collides with other region ID coming from # the regular DERP config. region_id:999
# Region code and name are displayed in the Tailscale UI to identify a DERP region region_code:"headscale" region_name:"Headscale Embedded DERP"
# Listens over UDP at the configured address for STUN connections - to help with NAT traversal. # When the embedded DERP server is enabled stun_listen_addr MUST be defined. # # For more details on how this works, check this great article: https://tailscale.com/blog/how-tailscale-works/ stun_listen_addr:"0.0.0.0:3478"
# List of externally available DERP maps encoded in JSON urls: -https://controlplane.tailscale.com/derpmap/default
# Locally available DERP map files encoded in YAML # # This option is mostly interesting for people hosting # their own DERP servers: # https://tailscale.com/kb/1118/custom-derp-servers/ # # paths: # - /etc/headscale/derp-example.yaml paths: []
# If enabled, a worker will be set up to periodically # refresh the given sources and update the derpmap # will be set up. auto_update_enabled:true
# How often should we check for DERP updates? update_frequency:24h
# Disables the automatic check for headscale updates on startup disable_check_updates:false
# Time before an inactive ephemeral node is deleted? ephemeral_node_inactivity_timeout:30m
# Period to check for node updates within the tailnet. A value too low will severely affect # CPU consumption of Headscale. A value too high (over 60s) will cause problems # for the nodes, as they won't get updates or keep alive messages frequently enough. # In case of doubts, do not touch the default 10s. node_update_check_interval:10s
# SQLite config db_type:sqlite3
# For production: # db_path: /var/lib/headscale/db.sqlite db_path:./db.sqlite
# # Postgres config # If using a Unix socket to connect to Postgres, set the socket path in the 'host' field and leave 'port' blank. # db_type: postgres # db_host: localhost # db_port: 5432 # db_name: headscale # db_user: foo # db_pass: bar
# If other 'sslmode' is required instead of 'require(true)' and 'disabled(false)', set the 'sslmode' you need # in the 'db_ssl' field. Refers to https://www.postgresql.org/docs/current/libpq-ssl.html Table 34.1. # db_ssl: false
### TLS configuration # ## Let's encrypt / ACME # # headscale supports automatically requesting and setting up # TLS for a domain with Let's Encrypt. # # URL to ACME directory acme_url:https://acme-v02.api.letsencrypt.org/directory
# Email to register with ACME provider acme_email:""
# Domain name to request a TLS certificate for: tls_letsencrypt_hostname:""
# Path to store certificates and metadata needed by # letsencrypt # For production: # tls_letsencrypt_cache_dir: /var/lib/headscale/cache tls_letsencrypt_cache_dir:./cache
# Type of ACME challenge to use, currently supported types: # HTTP-01 or TLS-ALPN-01 # See [docs/tls.md](docs/tls.md) for more information tls_letsencrypt_challenge_type:HTTP-01 # When HTTP-01 challenge is chosen, letsencrypt must set up a # verification endpoint, and it will be listening on: # :http = port 80 tls_letsencrypt_listen:":http"
## Use already defined certificates: tls_cert_path:"" tls_key_path:""
log: # Output formatting for logs: text or json format:text level:info
# Path to a file containg ACL policies. # ACLs can be defined as YAML or HUJSON. # https://tailscale.com/kb/1018/acls/ acl_policy_path:""
## DNS # # headscale supports Tailscale's DNS configuration and MagicDNS. # Please have a look to their KB to better understand the concepts: # # - https://tailscale.com/kb/1054/dns/ # - https://tailscale.com/kb/1081/magicdns/ # - https://tailscale.com/blog/2021-09-private-dns-with-magicdns/ # dns_config: # Whether to prefer using Headscale provided DNS or use local. override_local_dns:true
# List of DNS servers to expose to clients. nameservers: -1.1.1.1
# NextDNS (see https://tailscale.com/kb/1218/nextdns/). # "abc123" is example NextDNS ID, replace with yours. # # With metadata sharing: # nameservers: # - https://dns.nextdns.io/abc123 # # Without metadata sharing: # nameservers: # - 2a07:a8c0::ab:c123 # - 2a07:a8c1::ab:c123
# Split DNS (see https://tailscale.com/kb/1054/dns/), # list of search domains and the DNS to query for each one. # # restricted_nameservers: # foo.bar.com: # - 1.1.1.1 # darp.headscale.net: # - 1.1.1.1 # - 8.8.8.8
# Search domains to inject. domains: []
# Extra DNS records # so far only A-records are supported (on the tailscale side) # See https://github.com/juanfont/headscale/blob/main/docs/dns-records.md#Limitations # extra_records: # - name: "grafana.myvpn.example.com" # type: "A" # value: "100.64.0.3" # # # you can also put it in one line # - { name: "prometheus.myvpn.example.com", type: "A", value: "100.64.0.3" }
# Whether to use [MagicDNS](https://tailscale.com/kb/1081/magicdns/). # Only works if there is at least a nameserver defined. magic_dns:true
# Defines the base domain to create the hostnames for MagicDNS. # `base_domain` must be a FQDNs, without the trailing dot. # The FQDN of the hosts will be # `hostname.user.base_domain` (e.g., _myhost.myuser.example.com_). base_domain:example.com
# Unix socket used for the CLI to connect without authentication # Note: for production you will want to set this to something like: # unix_socket: /var/run/headscale.sock unix_socket:./headscale.sock unix_socket_permission:"0770" # # headscale supports experimental OpenID connect support, # it is still being tested and might have some bugs, please # help us test it. # OpenID Connect # oidc: # only_start_if_oidc_is_available: true # issuer: "https://your-oidc.issuer.com/path" # client_id: "your-oidc-client-id" # client_secret: "your-oidc-client-secret" # # Alternatively, set `client_secret_path` to read the secret from the file. # # It resolves environment variables, making integration to systemd's # # `LoadCredential` straightforward: # client_secret_path: "${CREDENTIALS_DIRECTORY}/oidc_client_secret" # # client_secret and client_secret_path are mutually exclusive. # # Customize the scopes used in the OIDC flow, defaults to "openid", "profile" and "email" and add custom query # parameters to the Authorize Endpoint request. Scopes default to "openid", "profile" and "email". # # scope: ["openid", "profile", "email", "custom"] # extra_params: # domain_hint: example.com # # List allowed principal domains and/or users. If an authenticated user's domain is not in this list, the # authentication request will be rejected. # # allowed_domains: # - example.com # Groups from keycloak have a leading '/' # allowed_groups: # - /headscale # allowed_users: # - alice@example.com # # If `strip_email_domain` is set to `true`, the domain part of the username email address will be removed. # This will transform `first-name.last-name@example.com` to the user `first-name.last-name` # If `strip_email_domain` is set to `false` the domain part will NOT be removed resulting to the following # user: `first-name.last-name.example.com` # # strip_email_domain: true
# Logtail configuration # Logtail is Tailscales logging and auditing infrastructure, it allows the control panel # to instruct tailscale nodes to log their activity to a remote server. logtail: # Enable logtail for this headscales clients. # As there is currently no support for overriding the log server in headscale, this is # disabled by default. Enabling this will make your clients send logs to Tailscale Inc. enabled:false
# Enabling this option makes devices prefer a random port for WireGuard traffic over the # default static port 41641. This option is intended as a workaround for some buggy # firewall devices. See https://tailscale.com/kb/1181/firewalls/ for more information. randomize_client_port:false
# For production: # /var/lib/headscale/private.key private_key_path:/var/lib/headscale/private.key
直接改成绝对路径就好了,还有两个文件路径 另一个也是个秘钥的路径问题
1 2 3 4 5 6 7 8 9
noise: # The Noise private key is used to encrypt the # traffic between headscale and Tailscale clients when # using the new Noise-based protocol. It must be different # from the legacy private key. # # For production: # private_key_path: /var/lib/headscale/noise_private.key private_key_path:/var/lib/headscale/noise_private.key
第二个问题
这个问题也是一种误导, 错误信息是
1
Error initializing error="unable to open database file: out of memory (14)"
这就是个文件,内存也完全没有被占满的迹象,原来也是文件路径的问题
1 2 3
# For production: # db_path: /var/lib/headscale/db.sqlite db_path:/var/lib/headscale/db.sqlite
 ,假如我的 U 盘的盘符是
,假如我的 U 盘的盘符是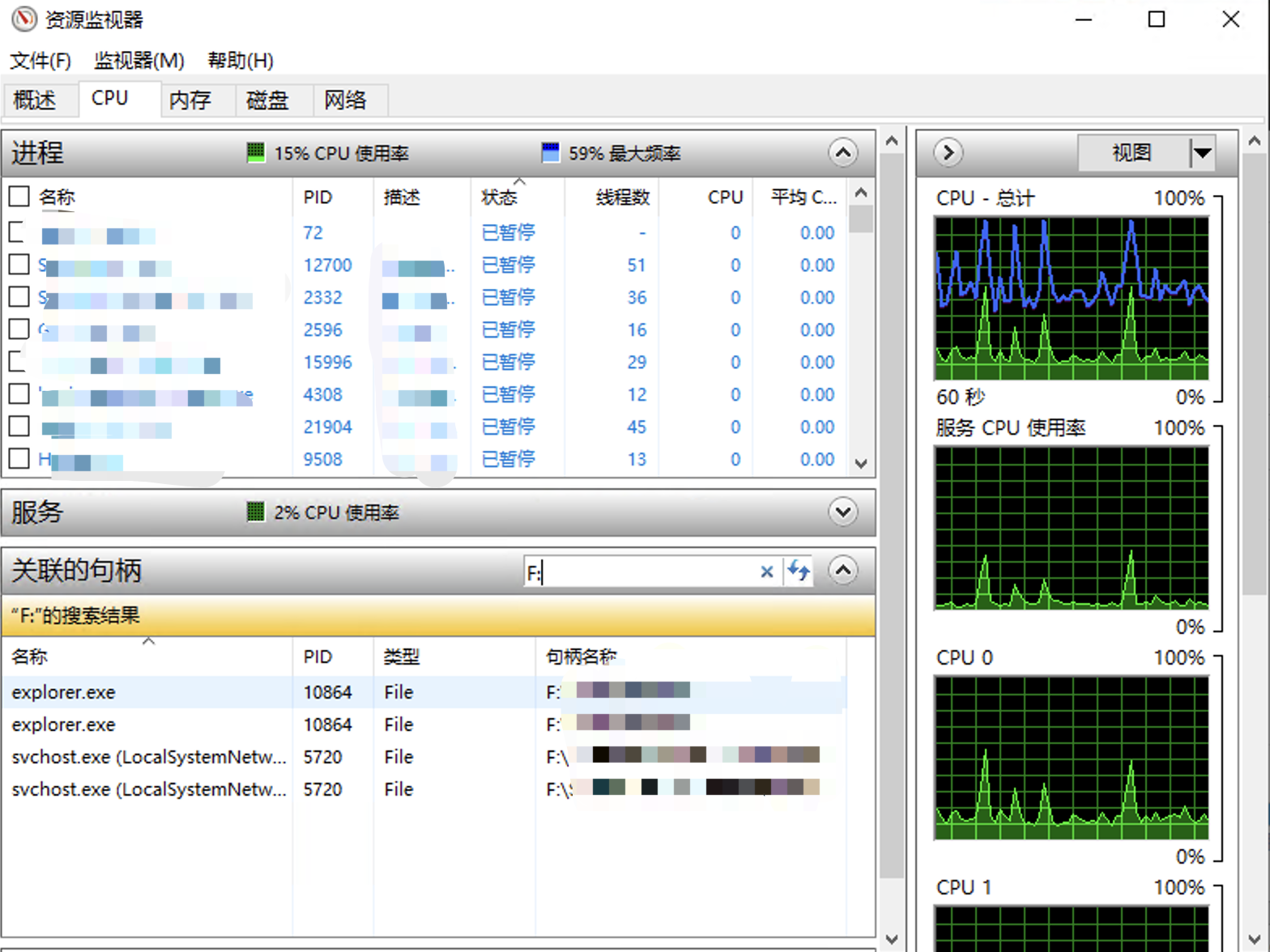 就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。
就可以搜索到占用这个盘符下文件的进程,这里千万小心‼️‼️,不可轻易杀掉这些进程,有些系统进程如果轻易杀掉会导致蓝屏等问题,不可轻易尝试,除非能确认这些进程的作用。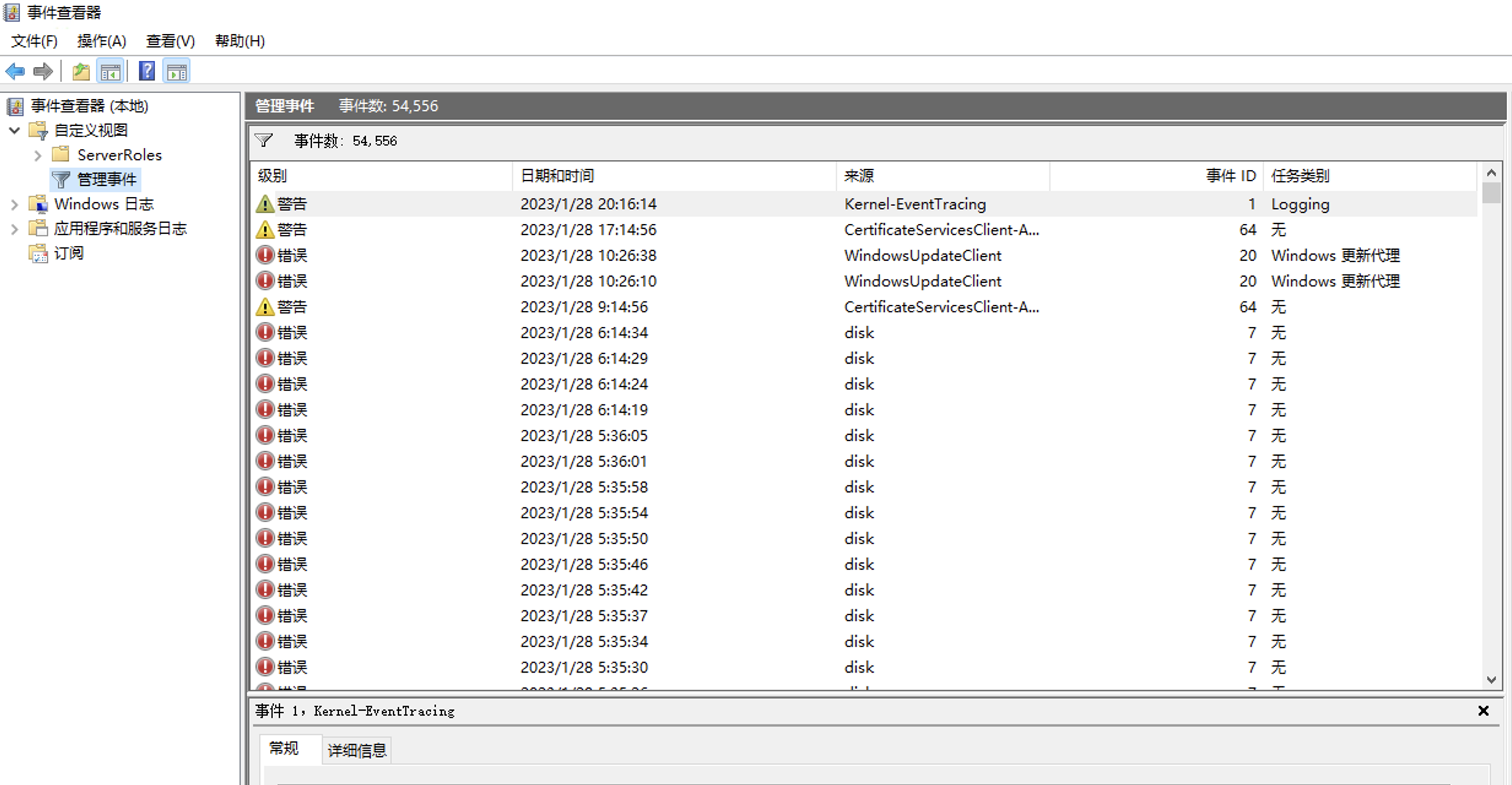 ,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息
,这个可以看到当前最近 Windows 发生的事件,打开这个后就点击U盘推出,因为推不出来也是一种错误事件,点击下刷新就能在这看到具体是因为什么推出不了,具体的进程信息