前两天拜读了章亦春大佬的关于Dynamic Tracing的文章,觉得对现在碰到的一些问题有了一些新的思考,为了能有所产出就先写一点简单的学习记录
首先这个systemtap类似于一个linux系统层面的探针工具,可以让用户去监控系统的各种活动
以阿里云的 ubuntu 22.04 为例,
首先我们需要安装 systemtap-sdt-dev 这个包,
然后因为通过c的方式比较常规,我是想研究下针对像 php 这种怎么去监控
我们需要一个编译参数带上--enable-dtrace 的php版本
然后在编译完后我们写一个简单的测试脚本1
2
3
4
5
6
| <?php
function a($b, $c) {
return $b + $c;
}
sleep(1);
echo a(1, 2);
|
这其实主要是为了触发系统调用
然后重点就是systemtap的脚本,它有点类似于c的代码,结构主要是 “事件” - “处理器”
比如我监听到了php发起了一个系统调用,那这个时候我想把它记录下来,打印日志这种1
2
3
4
5
6
| probe syscall.*
{
if (execname() == "php") {
printf ("%s(%d) open, call %s \n", execname(), pid(), name)
}
}
|
这里就是针对所有的系统调用,如果是由php发起调用,那就打印出来pid和系统调用的名字(name就是这里的系统调用名字)
事件
syscall.system_call 只是其中一类事件
还有对虚拟文件系统的操作 vfs.file_operation
内核的方法调用 kernel.function("function")
比如 probe kernel.function("*@net/socket.c") { }
还有可以是内核的一些追踪点
kernel.trace("tracepoint")
比如 kernel.trace("kfree_skb") 这个表示每次当内核中的network buffer被释放的时候触发
还有的是时间时间
timer events
比如1
2
3
4
| probe timer.s(4)
{
printf("hello world\n")
}
|
每4秒打印一个 hello world
还有这些1
2
3
4
5
| timer.ms(milliseconds)
timer.us(microseconds)
timer.ns(nanoseconds)
timer.hz(hertz)
timer.jiffies(jiffies)
|
处理器
最常规的一类就是打印信息了
printf ( ) Statements
这个跟c语言也很像,可以用%s 跟 %d 作为占位符来填充字符串和数字
然后就是一些定义好的取值方法
execname() (a string with the executable name)
就比如刚才的php,
线程id1
2
| tid()
The ID of the current thread.
|
用户id1
2
| uid()
The ID of the current user.
|
比如系统调用就直接用 name
还有很多可以研究,第一篇学习就先到这里
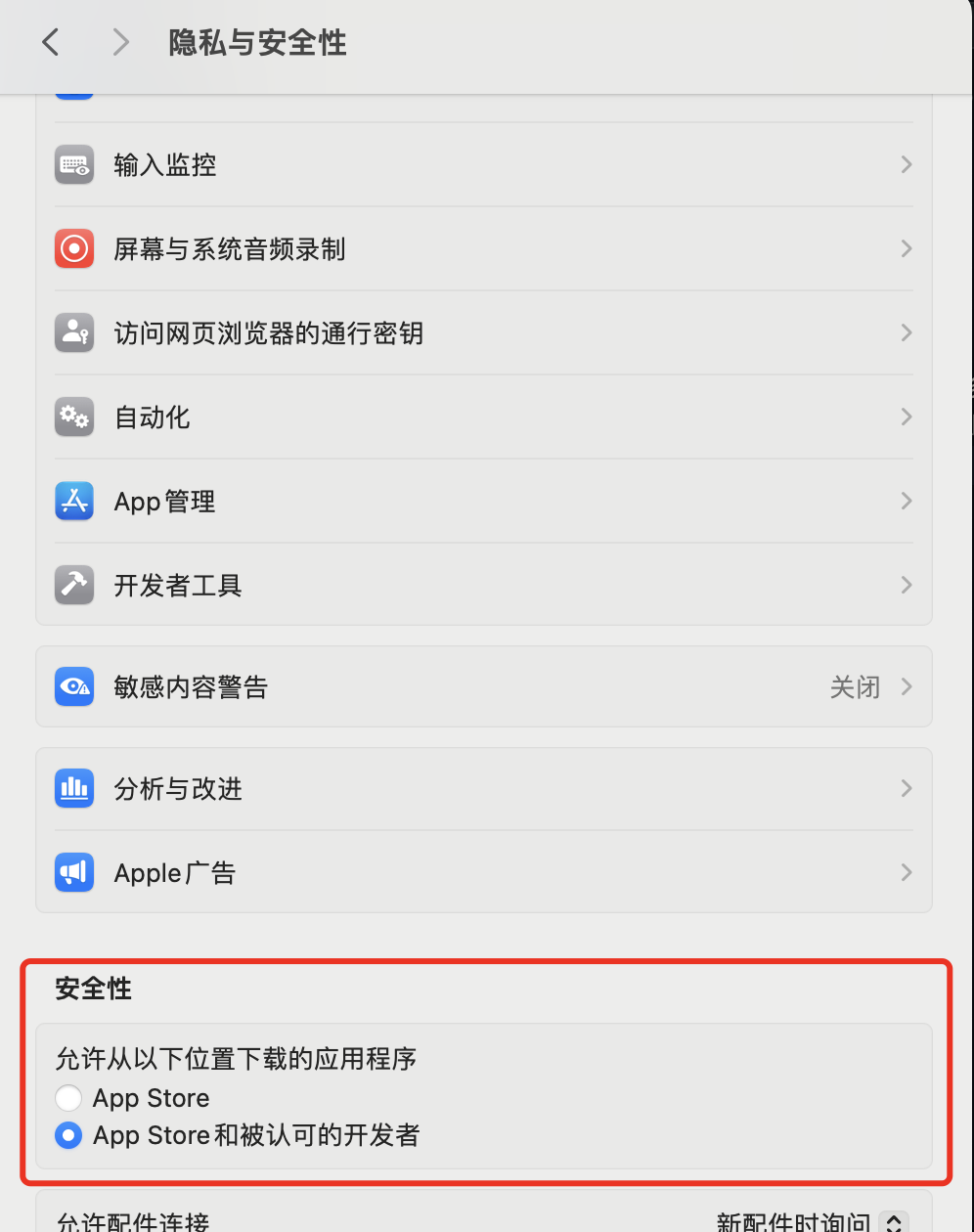
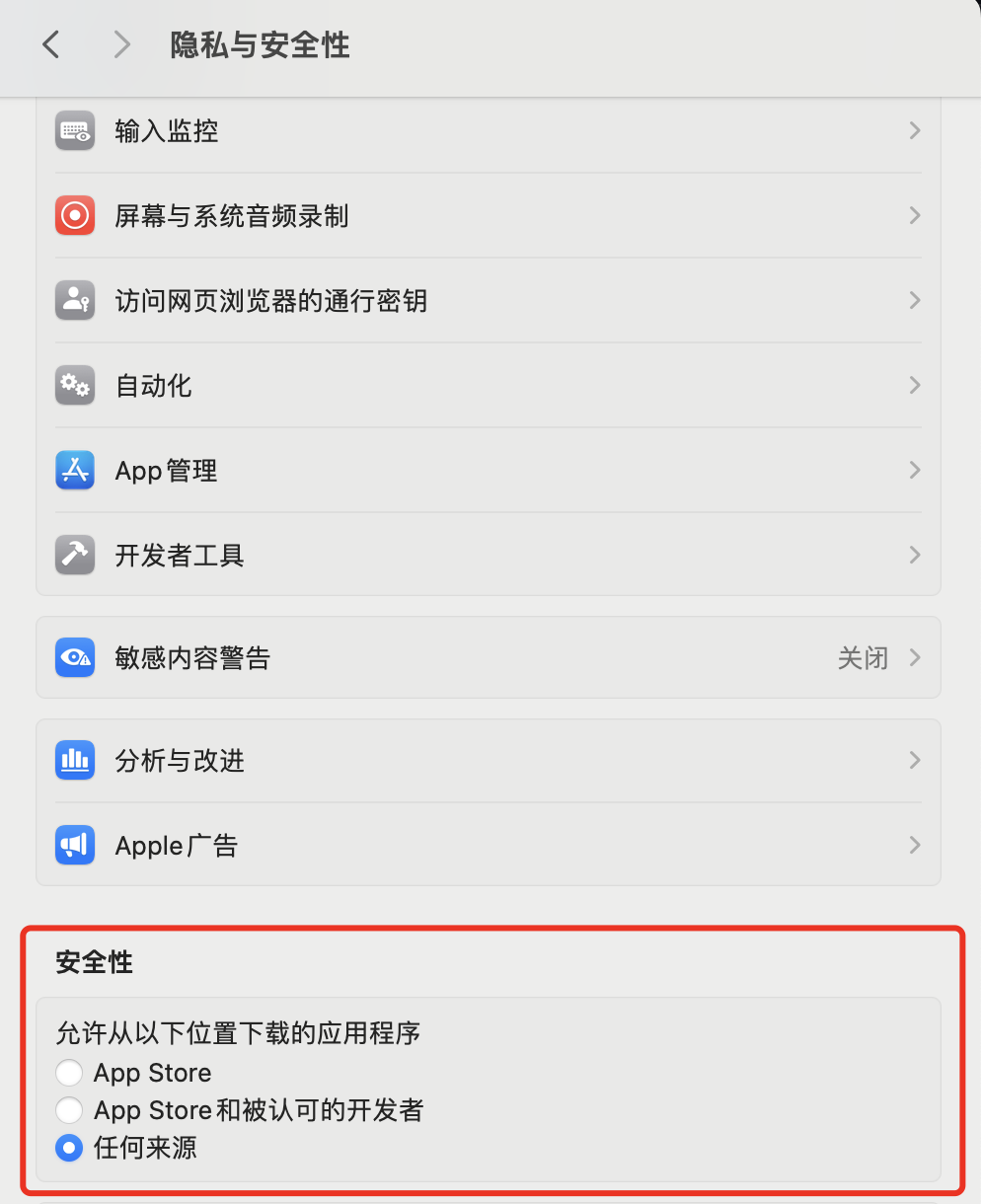
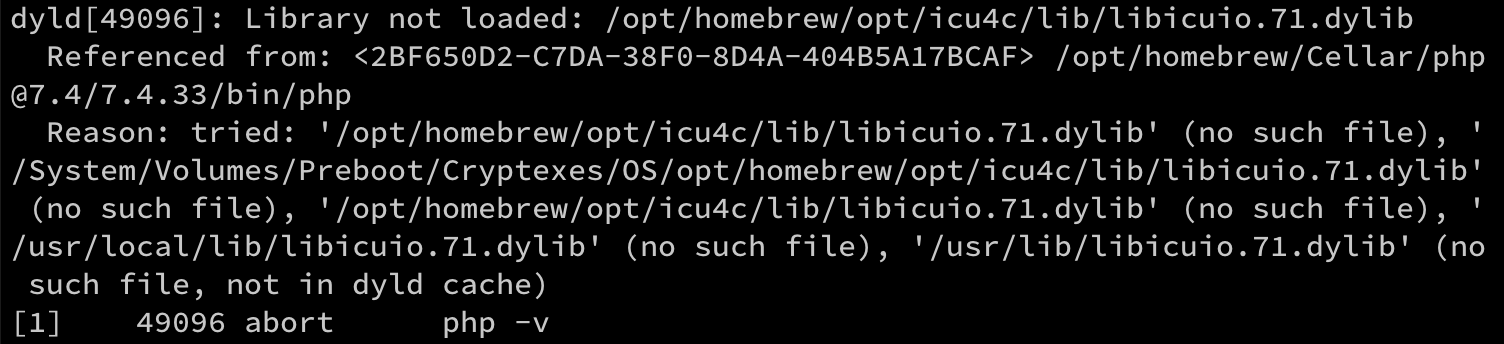 , 正好又解决了下
, 正好又解决了下