nvm use v18 npm install -g @anthropic-ai/claude-code
安装以后到想要开发的项目 运行
1
claude
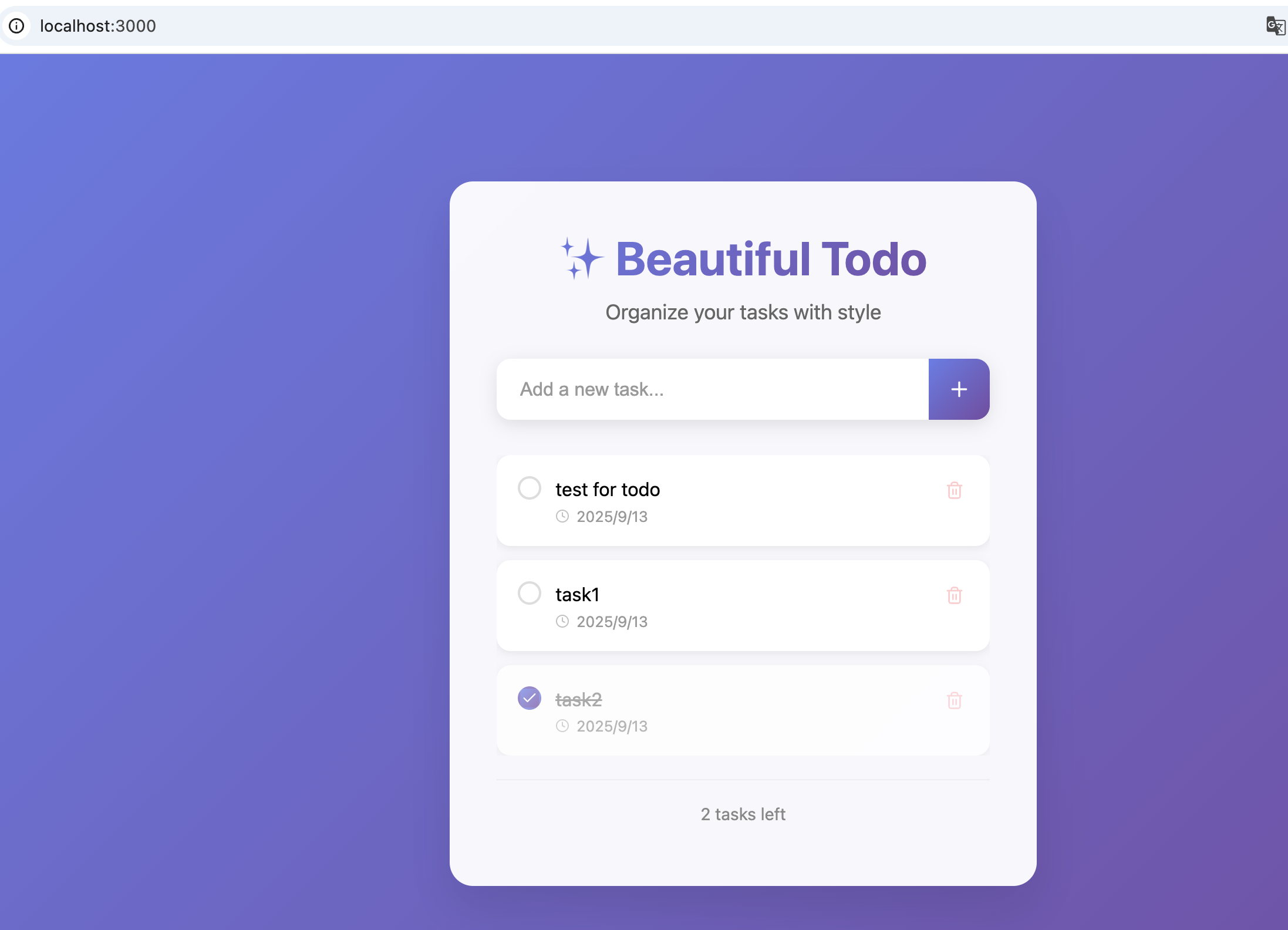
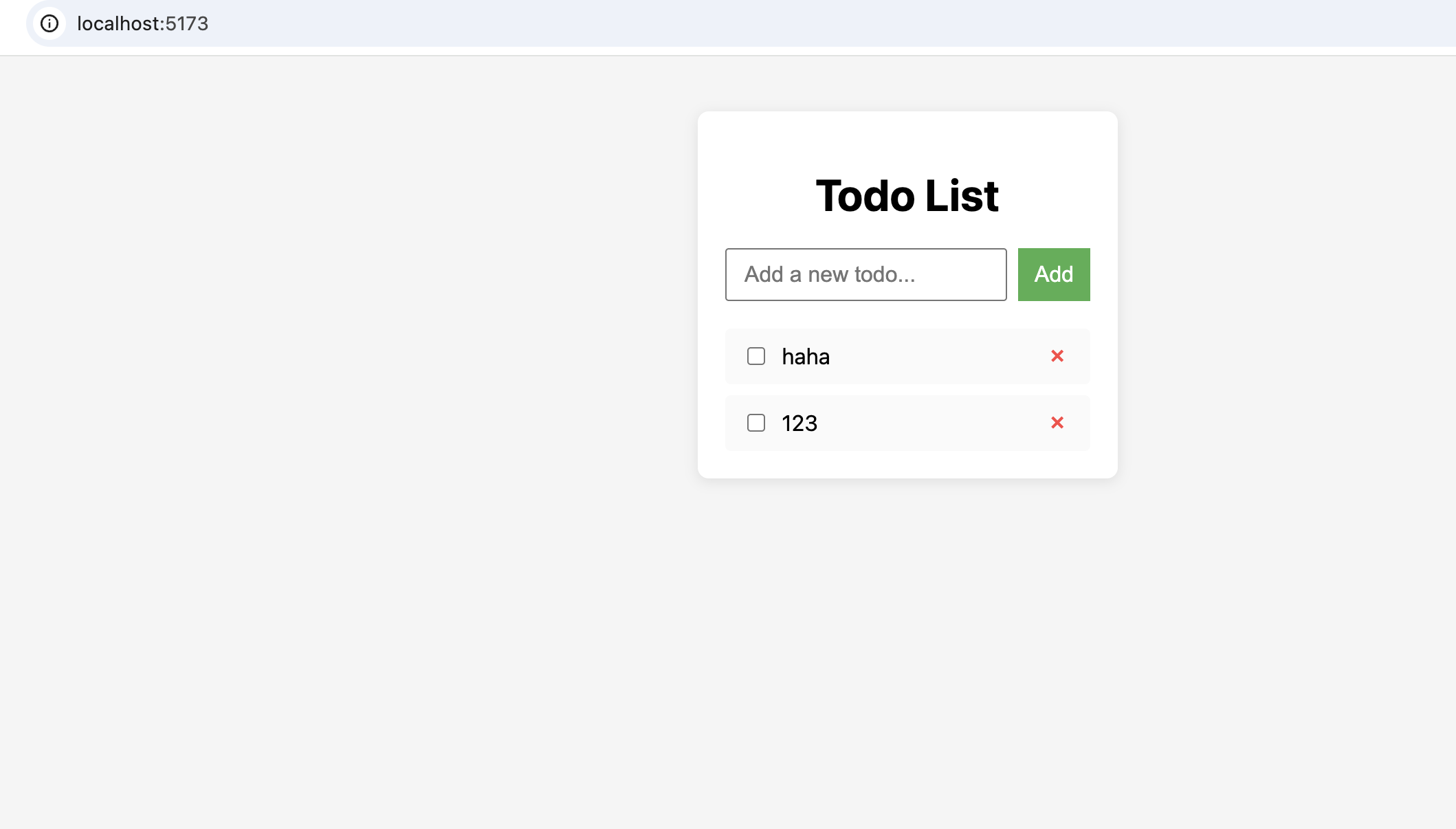
接下来我们同样以todo应用作为测试应用
1
帮我写一个todo应用,使用react,ui需要尽可能美观
只是加了个美观的要求
1 2 3 4 5 6 7 8
⏺ Update Todos ⎿ ☐ Set up React project structure and dependencies ☐ Create main Todo component with state management ☐ Design and implement beautiful UI with CSS/styling ☐ Add todo functionality (add, delete, toggle complete) ☐ Test the application
⏺ Let me start by checking the current directory structure and then create the React todo application.
Thinking... The user asks in Chinese: "怎么成为Java架构师" which means "How to become a Java architect?" They likely want steps, skills, learning path. Provide a thorough guide: fundamentals, design patterns, architecture frameworks, deep dive, system design, cloud, CI/CD, soft skills, leadership, etc. Also talk about certifications, real-world experience, project, mentorship, portfolio. Cover common architecture patterns: microservices, distributed, event-driven. Tools: Spring, Hibernate, etc. Should also mention reading books: Clean Architecture, Domain-Driven Design, Patterns. Also cover continuous learning, speaking at conferences, writing blogs.
Let's structure answer: introduction, prerequisites, technical skills, architectural concepts, real-world experience, soft skills, certifications, community, portfolio, continuous learning. Provide resources and timelines. Since Chinese user, answer in Chinese. Provide details, resources links. Make it thorough. Use bullet points for clarity.
Okay, let's break down how to learn Java! It can seem daunting at first, but with a structured approach, you'll be coding in Java in no time. Here’s a breakdown of a recommended learning path, broken down into phases: **1. Foundation (2-4 Weeks)** * **Understand the Basics:** * **What is Java?** Java is a robust, object-oriented programming language known for its platform independence ("write once, run anywhere"). It’s used for enterprise applications, Android development, and more. * **Why Learn Java?** It’s a popular choice for beginners because it’s relatively easy to learn, has a large community, and is used in many real-world applications. * **Key Concepts:** * **Variables & Data Types:** Understand different data types (int, float, String, boolean, etc.). * **Operators:** Arithmetic, comparison, logical, assignment. * **Control Flow:**`if`, `else`, `for`, `while` – controlling the flow of your program. * **Basic Syntax:** The code structure of Java. * **Resources:** * **Tutorialspoint Java Course:** [https://www.tutorialspoint.com/java/index.htm](https://www.tutorialspoint.com/java/index.htm) - A good, comprehensive, and free overview. * **Codecademy's Learn Java:** [https://www.codecademy.com/learn/learn-java](https://www.codecademy.com/learn/learn-java) - Interactive, hands-on exercises. * **Google's Java Tutorial:** [https://developer.android.com/training/jdbc](https://developer.android.com/training/jdbc) (Java is built on JDBC, so this will give you a baseline) **2. Core Concepts (4-8 Weeks)** * **Data Structures:** * **Arrays:** Fundamental data structures. Understand how to declare, initialize, and use arrays. * **Linked Lists:** Another essential data structure, offering flexibility. * **Object-Oriented Programming (OOP) Fundamentals:** * **Classes and Objects:** The basis of OOP. Learn how to define classes, create objects, and interact with them. * **Encapsulation:** Bundling data and methods that operate on that data within a class. * **Inheritance:** Creating new classes based on existing classes. * **Polymorphism:** The ability of objects to take on many forms. * **Java Syntax & Semantics:** * **Statements:** The commands you write. * **Expressions:** Results of calculations. * **Keywords:** Reserved words with special meanings (e.g., `class`, `if`, `else`). * **Comments:** Explain your code. * **Resources:** * **Oracle Java Tutorials:** [https://docs.oracle.com/javase/tutorial/](https://docs.oracle.com/javase/tutorial/) – A more in-depth guide. * **FreeCodeCamp's Java Tutorial:** [https://www.freecodecamp.org/learn/java-tutorial/](https://www.freecodecamp.org/learn/java-tutorial/) - Great for visual learners. **3. Practical Application - Projects** * **Simple Programs:** Start with small, manageable projects: * **Number Guessing Game:** A classic introductory project. * **Rock-Paper-Scissors:** A basic example of OOP. * **Simple Calculator:** Reinforces fundamental concepts. * **Gradually Increase Complexity:** * **Print Statements:** A simple way to understand output. * **Palindrome Checker:** A challenge to practice string manipulation. * **Basic Console Applications:** Write programs that run directly in the console. **4. Intermediate Concepts (Ongoing)** * **Exception Handling:** Understanding and handling errors. * **Collections:** Learn about ArrayLists, LinkedLists, Sets, and Maps. * **String Manipulation:** Working with strings effectively. * **Multithreading:** Understanding how to run multiple tasks concurrently (basic concepts). * **Java Collections Framework:** The cornerstone of modern Java programming. **Resources for Continued Learning:** * **Stack Overflow:** [https://stackoverflow.com/](https://stackoverflow.com/) - An invaluable resource for solving coding problems and learning from others. * **Reddit's r/java:** [https://www.reddit.com/r/java/](https://www.reddit.com/r/java/) - A community forum with discussions and resources. * **YouTube:** Search for Java tutorials and courses (e.g., "Java for beginners"). **Tips for Success:** * **Practice Regularly:** Even 30 minutes a day is better than long, infrequent sessions. * **Write Code Frequently:** The more you write, the better you'll understand. * **Don't Be Afraid to Make Mistakes:** Mistakes are part of the learning process. Learn from them. * **Read Code:** Look at code written by others to understand different approaches. * **Join a Community:** Connecting with others can provide support and motivation. **To help me tailor my advice even more, could you tell me:** * **What's your background in programming?** (e.g., Have you programmed before? If so, what languages?) * **What are your goals for learning Java?** (e.g., Career change? Personal project? Specific application like Android?)