关于适合什么模型,推荐下llmfit
上次我是实地使用llama.cpp跑了本地大模型,这种测试成本比较大,
刚好上次看到有个软件可以运行在本地来评估当前机器的性能可以跑什么样的大模型
它就是llmfit
在mac可以使用1
brew install llmfit
windows可以1
scoop install llmfit
安装好就可以直接运行了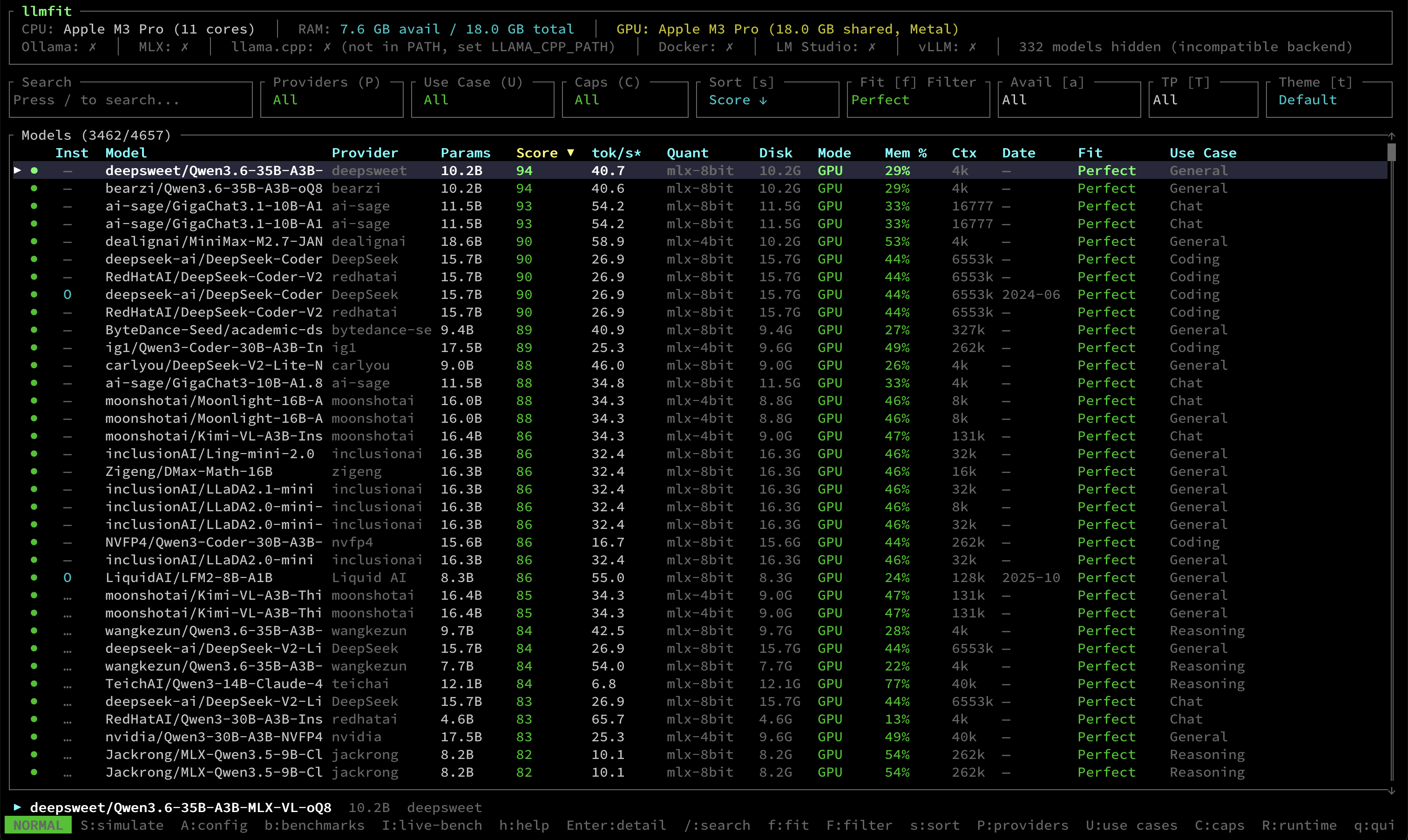
可以看到有列了很多模型,包括参数量,token速度,占用磁盘大小,内存占用率,上下文大小等等
这样就很容易能看到我的电脑能跑什么样的模型,另外比较重要的是内存和硬盘的占用,
因为当我们真正使用的时候,除非这个电脑就被定位是只用来跑模型,不然我们一般也还会有同时在电脑上运行的程序
比如要一边写点文章,看会视频等,比如占用个50%的内存那差不多,如果要90%这种,显然是不太实际的
还有上下文长度,如果要运行对应的agent的话,还需要保障基础的上下文长度
它的原理主要是通过硬件驱动接口来识别当前设备的配置情况
比如n卡的话就是nvidia-smi,1
2
3
4
5
6llmfit在启动时使用sysinfo(用于RAM和CPU)和特定于供应商的工具组合读取你的系统规格:
NVIDIA:查询nvidia-smi,为多GPU设置聚合所有检测到的GPU的显存
AMD:通过rocm-smi检测
Intel Arc:从sysfs读取独立显存,通过lspci集成
Apple Silicon:通过system_profiler读取统一内存(显存 = 系统RAM,因为是共享池)
它还识别正在使用的加速后端——CUDA、Metal、ROCm、SYCL或CPU(ARM/x86)——,因为这直接影响速度估计。