浅析下mysql的索引的基数与可选择性
最近也看到了一篇文章,结合一些实际的经验来看下索引的基数和可选择性,
这个基数指的是啥呢,就是索引我们一直在讲的是要字段值的差异度比较大的那种,因为假如这个字段的所有值都是比如0和1的话,那索引的结构BTree就没办法高效的找到所查询的值,这个基数就是可以作为它差异度大小的一个参考,当然这是一种反过来的说法,理论上应该从写入这个表的数据的逻辑去看,这些字段会出现哪些值以及它的取值范围是怎么样的
那么这个会在mysql中存起来的基数值可以怎么看呢
还是用我之前建的一个简单的表1
2
3
4
5
6
7
8
9
10CREATE TABLE `students` (
`id` bigint(32) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(64) NOT NULL COMMENT '姓名',
`age` int(11) NOT NULL COMMENT '年纪',
`class` int(11) NOT NULL COMMENT '班级',
`created_at` datetime NOT NULL COMMENT '创建时间',
`updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_class` (`class`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=608 DEFAULT CHARSET=utf8mb4 COMMENT='学生表';
表里的数据也比较简单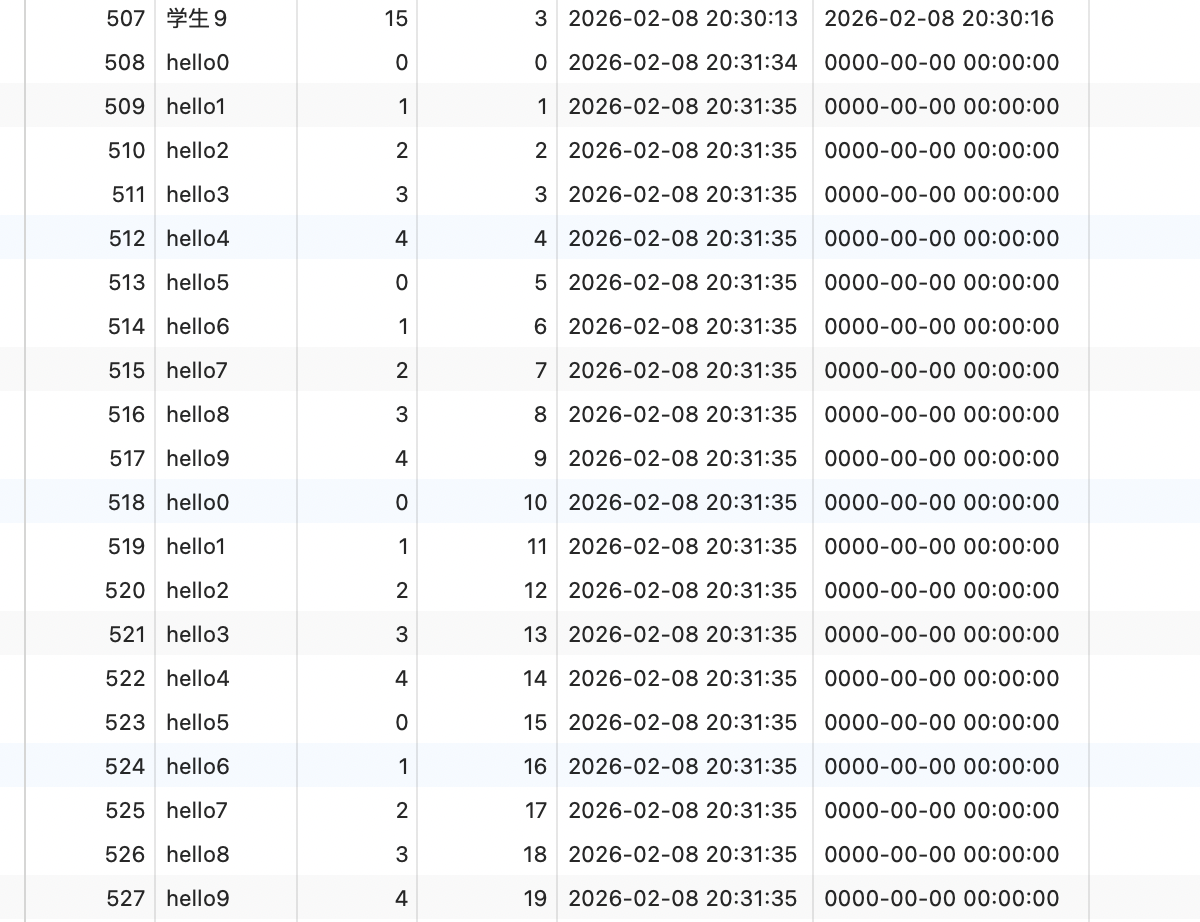
因为升成name和class的时候我都用了一定的规律取余,所以会有一些重复的,
这是我们就可以在information库的查一下这个基数1
select table_schema,table_name,index_name,cardinality from information_schema.statistics where table_schema='database' and table_name = 'students' order by cardinality desc
database是你的库,可以来这么查询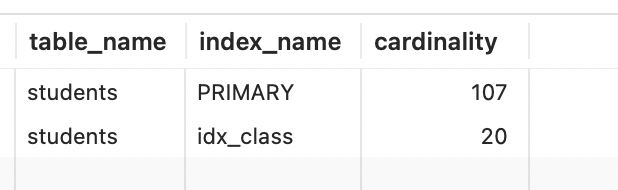
我的这个表差不多是这样,主键刚好对应的就是数据量,另一个班级的索引就是这个class的数量是一致的
所以这就是个明确的区分度的值,而之前也提到过,如果一个表的某个索引字段他的区分度低,跟全表扫描差不多的话
优化器当然也可能会选择不使用索引,直接使用全表扫描,这样就不用质疑说为啥没用起来索引等等