使用 LM Studio 在本地部署 Deepseek-R1 的蒸馏版大模型
deepseek-v3 和 deepseek-r1 是由深度求索公司推出的大语言模型,并且在生成效果上基本已经到达国内甚至全球的顶级水准,并且是免费使用,并且是开源的
连着用三个并且不是我文字能力差,而是真的佩服deepseek这家公司和创始人梁文峰,作为校友感觉是真的忝列门墙
早先了解的幻方量化就是一家小众低调但又多金的公司,奈何都是招的全栈工程师,可能不是太适合,当前对于deepseek来说那就更遥远了,从公开的不一定可靠的信息来看,目前在deepseek的都是像清北的博士这样的顶级人才,而且在人工智能这块,只是浅显地涉及过一些机器学习相关的工作,对于最前沿的大模型这块着实还有比较大的差距,当然也是在学习中。
虽然不是完全专业,但是对比大部分跟这个领域完全不相关的人来说,可能还是可以给出一些半专业的见解
首先例如 deepseek 只使用了很少的显卡来训练这一点也只是相对的,比如最新出的 grok 3 的20万卡,的确省了比较多资源,使用了2048张H800显卡,说实话这个也不是任何公司可以负担得起的,训练的总成本估计是560万美元,H800的价格预计在20万-40万元,后期因为禁售等可能涨价至后者,即使以20万一张的价格,光显卡的价格就需要4亿的资金,这不是随便一个公司就负担得起的,也得亏之前幻方就是靠机器学习做量化交易,原先就有显卡储备,并且盈利能力很强。
第二点是对于现在市面上乱七八糟的 deepseek 服务,因为实在太火了,导致 deepseek 的官方服务一直处于限流状态,然后就出现了各种说上线了 deepseek 大模型,以真实情况来讲除了少数几家本身就在做这个的,浑水摸鱼的存在比较多,例如用了 deepseek 的 api 接口的,或者是类似于我后面要讲的,只是部署了个蒸馏模型,因为全尺寸模型,再不用什么垃圾佬的省显卡黑科技的情况,671B的大小我通过 grok-3 的推理计算大概也需要 2000张H800显卡才能支持约100qps,这个可能也不是随便一家公司能负担得起的,并且还有这个带来的巨大能耗费用,只是把它跑起来因为模型文件有接近700G,那么至少需要 80G 现存的 H800 显卡 9张,为了推理效率更高,那要求就更高了。
而对于我们本地想使用这个模型的话,普通情况下也只能使用小尺寸的蒸馏后模型,这个效果肯定是跟deepseek官方和比如腾讯等大厂提供的全尺寸是没法比的,所以很多网上的视频和文章说教你本地部署 deepseek-r1 的绝大多数是这种蒸馏模型,因为普通人哪怕是最新的5090显卡也只有32G的显存,不可能载入全尺寸模型,按多卡算得 22 张 5090,我相信普通人很难搞到这么多显卡,并且常规的 U 有PCIE通道数量上线,单机不太可能能承载22张 5090。
而全尺寸的671B的模型跟常规家用电脑能跑起来的例如 7B 跟 14B 的差异类似于视频,480P的视频跟4K的视频,虽然都能看,但是效果来说还是差挺多,所以有些同学觉得官方的 deepseek 经常繁忙,而听信网上一堆文章说能直接在自己电脑上跑 deepseek-r1 的,可能还是以忽悠为主。本地自己的家用电脑部署主要是能够方便的使用例如 deepseek-r1 的小参数量蒸馏版本,来提供一些非高标准的要求,以及一些学习目的,比如我们可以在本地部署一个 7b 或者 14b 版本的模型,然后再基于这个模型加上 RAG 功能,这样就能把我们平常躺在那的笔记跟知识库变成一个能够更高效的提供知识检索的高级知识库。
这里我们使用LM Studio 在Windows 环境下部署一个 7b的蒸馏模型,比如 lmstudio-community/DeepSeek-R1-Distill-Qwen-7B-GGUF/DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf 这个模型,
首先这个模型是基于 Qwen2.5-Math-7B 通过监督微调(SFT)从 DeepSeek-R1 生成的数据集上训练得到的。 所以基础模型来说它是有目的性的,主要为数学方向做的训练,在此基础上会学习到 deepseek-r1 的推理能力
此前我们写过使用 ollama 来在本地跑谷歌开源的 Gemma 模型,因为 deepseek-r1 的这些蒸馏模型在ollama的支持没那么快,所以我是先用lm studio来跑了
Lm Studio 相比 ollama 来说是带有了 UI 界面的一个大模型运行软件,这样就更方便的可以开箱即用
从官网下载完安装完对应平台的 LM Studio 以后差不多是这样子, 我以Win10系统为例
默认还没有任何模型,我们可以点击左侧的搜索样图标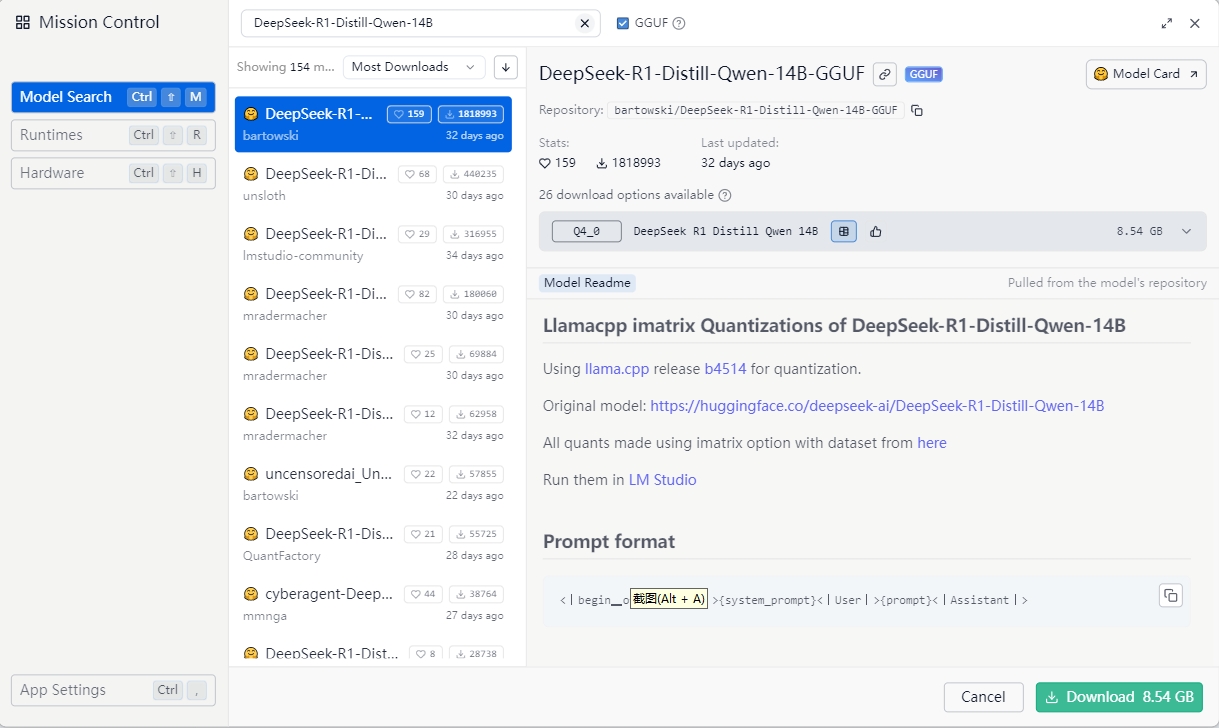
在这里可以进行模型的搜索,但是由于众所周知的原因,这个搜索模型的并不像ollama一样能够很顺畅地下载,一般国内网络是打不开的,或者说只有模型列表,但是无法打开详情页面,我们需要一些小操作
首先我们找到LM Studio的安装目录,例如我这样的 D:\Program Files\LM Studio 我的是自己修改过的,常规的方式可以在桌面 LM Studio 图标上右键,然后点击 “打开文件所在的位置” 就可以找到LM Studio 的安装目录了,然后继续打开安装目录中的 resources 文件夹,再打开其中的 app 目录,就可以看到一个 .webpack 文件夹,建议用 vscode 或者sublime 打开目录,然后全局搜索 huggingface.co 替换成镜像地址 hf-mirror.com,然后重新打开 LM Studio 就可以搜索到上面提到的模型了,可能是由于这个镜像站没那么充足的资源,一般是白天的下载速度会快一点,晚上一般速度不太行,有条件的可以上全局代理,不过幸好 LM Studio 是支持断点续传的,只是它的下载很容易超时后自动异常,并不会自动重试,,这是个比较头疼的地方。
下载完成后就可以在顶部选择模型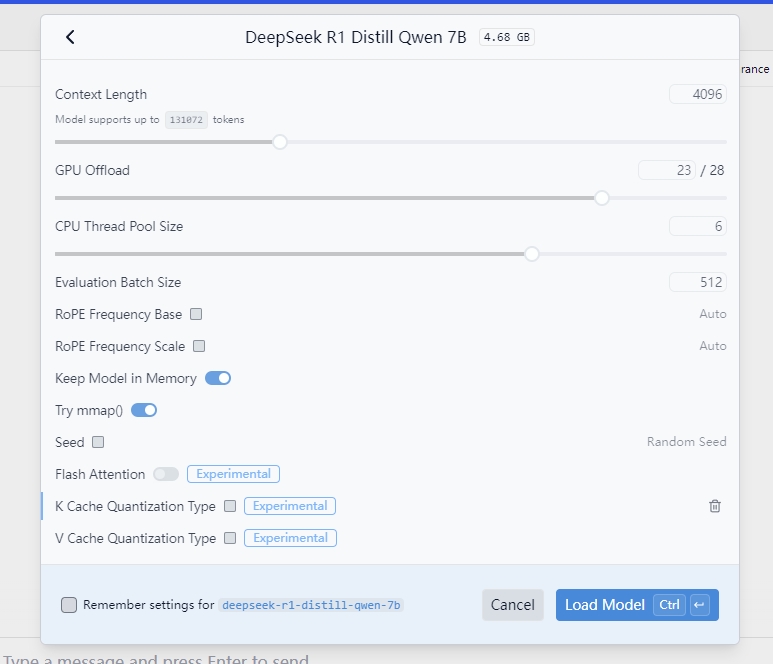
这里会有一些配置,比如显卡的超载情况,是否将模型完整载入内容,上下文长度,显卡我这边是笔记本上的 3060,只有6g的显存,所以用不了很大的模型,内存倒可以载入,但是除非只用cpu来运行,否则内存载入只是将从硬盘载入显存的速度加快了,因为普通的PC并不像Mac使用的是统一内存,当然目前好像有清华的团队已经搞出来使用kTransformer通过一张4090显卡加384G内存运行全尺寸的 deepseek-r1 ,这类暂时不考虑在内,如果只是一些简单的使用场景,可以把上下文的大小调小一些,这样可以加快生成速度
问一个比较简单的问题,也是我比较讨厌的问题9.11跟9.08 哪个大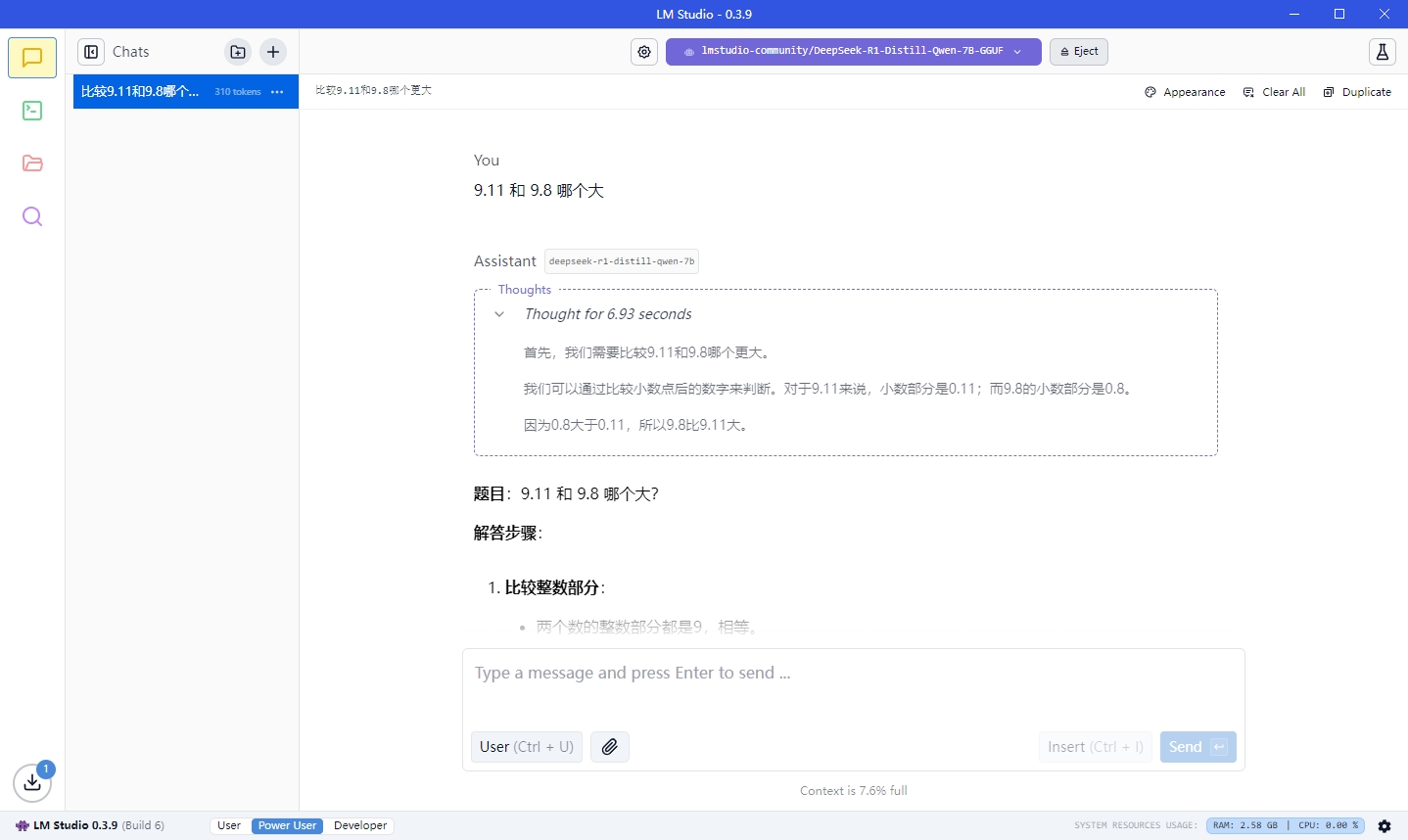
果然是以数学模型蒸馏出来的,其实很多用来话题讨论度比较高的用来比较大模型能力水平的都是比较没意义的,因为这种问题不依赖于大模型,甚至都不用搜索就能知道,会让这么大成本训练出来的大模型显得更加弱智,本身就不是为了这个而生的,唠叨的比较多,后面可以继续讲