尝试下图片向量化
之前觉得谷歌的以图搜图很厉害,现在似乎这个路径还毕竟清晰了,首先要有图片库,把它们向量化以后存储起来,然后对于目标图片也做向量化,再做检索
那么我们先来做重要的这一步,图片的向量化,因为向量化以后就跟图片没关系了,直接用前面讲到的向量的近似搜索就可以做到以图搜图了
这边我们用到了towhee工具,towhee是个机器学习的pipeline工具,可以做数据源(文件,图片,媒体,文本)–> 模型 –> 向量。
首先我们安装towhee1
pip install towhee towhee.models
这里有第一个坑,因为有torch依赖,但是目前torch支持的python版本是最高3.9,再往上可能就有问题了
所以我们要先创建一个3.9的环境1
conda create -n py9 python=3.9
然后我们会遇到第二个坑
就是milvus的客户端1
pip install pymilvus==2.3.0
再早的客户端会有依赖不支持,更新的客户端会连接不上
然后再在milvus创建一个Collection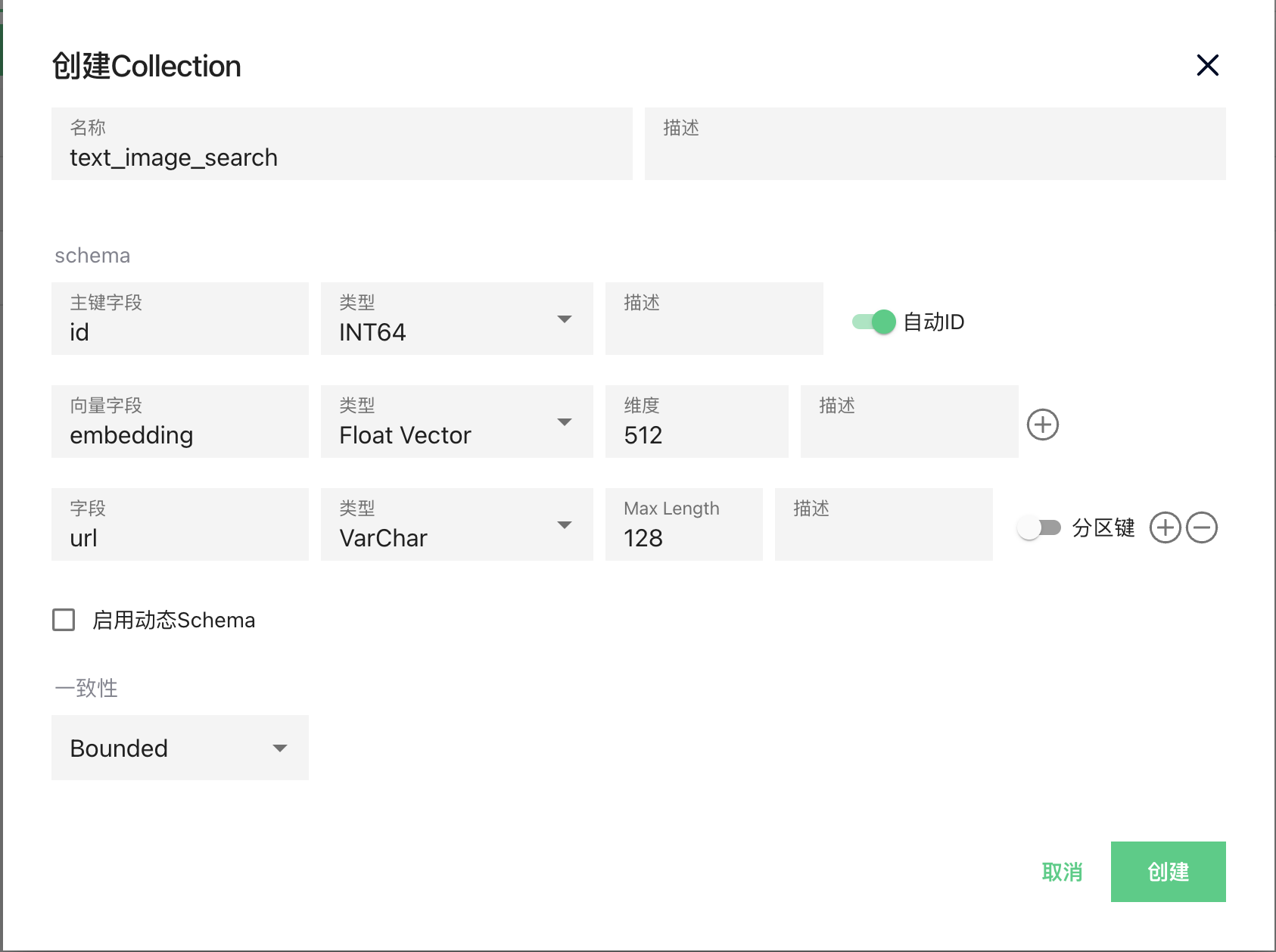
然后这个是不对的,因为我使用attu界面创建的,默认第二个字段一定得是向量字段,所以又用了上次的Java代码来创建1
2
3
4
5
6
7
8
9
10
11
12
13CreateCollectionReq.CollectionSchema collectionSchema = clientV2.createSchema();
// add two fileds, id and vector
Integer dim = 2048;
collectionSchema.addField(AddFieldReq.builder().fieldName("url").dataType(DataType.VarChar).build());
collectionSchema.addField(AddFieldReq.builder().fieldName("embedding").dataType(DataType.FloatVector).dimension(dim).build());
collectionSchema.addField(AddFieldReq.builder().fieldName("id").dataType(DataType.Int64).isPrimaryKey(Boolean.TRUE).autoID(Boolean.TRUE).description("id").build());
CreateCollectionReq req = CreateCollectionReq
.builder()
.collectionSchema(collectionSchema)
.collectionName("text_image_search")
.dimension(dim).build();
clientV2.createCollection(req);
并且注意字段顺序不能错,这个顺序在towhee的demo中也没地方直接修改
看一下towhee的demo
地址在这
https://towhee.io/tasks/detail/pipeline/text-image-search1
2
3
4
5
6
7
8
9
10
11
12
13from towhee import AutoPipes, AutoConfig
# set MilvusInsertConfig for the built-in insert_milvus pipeline
insert_conf = AutoConfig.load_config('insert_milvus')
insert_conf.collection_name = 'text_image_search'
insert_pipe = AutoPipes.pipeline('insert_milvus', insert_conf)
# generate embedding
embedding = image_embedding('./test1.png').get()[0]
# insert text and embedding into Milvus
insert_pipe(['./test1.png', embedding])
第三个坑,这并不能跑起来1
2
3 embedding = insert_pipe.image_embedding('./test.jpg').get()[0]
^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'RuntimePipeline' object has no attribute 'image_embedding'
因为找不到这个 image_embedding
估计是这个也是包路径变更了,但是并没有什么文档可以找到,之前LlamaIndex还有点更新指南,后来是问了Claude才知道了1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19from towhee import AutoPipes, AutoConfig, ops
# set MilvusInsertConfig for the built-in insert_milvus pipeline
insert_conf = AutoConfig.load_config('insert_milvus')
insert_conf.collection_name = 'text_image_search'
insert_pipe = AutoPipes.pipeline('insert_milvus', insert_conf)
# 创建图像嵌入管道
image_embedding_pipe = AutoPipes.pipeline('image-embedding')
# 生成嵌入
embedding = image_embedding_pipe('./test.jpg').get()[0]
# insert text and embedding into Milvus
insert_pipe(['./test.jpg', embedding])
需要从 AutoPipes 中把这个 image-embedding 找出来
然后就是上面说到的字段映射问题,默认是先url,再embedding字段,并且主键字段必须是autoId,不然也会缺少默认值,还是感叹下,工程化的东西还是要工程化的质量保证,否则变更都无从知晓,现在人工智能大热,大家都在追风,只是基础的软件还是要稳扎稳打,这样我们工程人员才能把它们更好的用起来,PS:娃真可爱,但真的好累