向量数据库学习-介绍一下HNSW算法
结合AI写的一篇HNSW的介绍文章,算是向量数据库中比较核心的算法
1. 引言
向量数据库在当今人工智能和机器学习领域扮演着越来越重要的角色。随着数据规模的不断扩大和应用场景的日益复杂,传统的数据库系统已经难以满足高维向量数据的快速检索需求。在这个背景下,近似最近邻(Approximate Nearest Neighbor, ANN)搜索问题成为了一个热点研究方向。
HNSW(Hierarchical Navigable Small World)算法是解决ANN问题的一种高效方法。它通过构建一个多层次的图结构,结合小世界网络的特性,实现了对高维向量数据的快速、精确检索。本文将深入浅出地介绍HNSW算法的核心思想、工作原理以及实际应用。
2. HNSW算法的核心思想
HNSW算法的核心思想可以概括为三个关键点:分层结构、小世界图和近似搜索。
分层结构
HNSW采用了一种多层次的图结构。想象一下,如果我们要在一个大城市中找到一个特定的地址,我们通常会先看城市地图,然后逐步缩小范围到区、街道,最后定位到具体门牌号。HNSW的分层结构就类似于这种由粗到细的搜索过程。这个就是之前介绍跳表的目的,就是现在稀疏的结构里可以快速定位,然后再往下层进行搜索,提高了搜索效率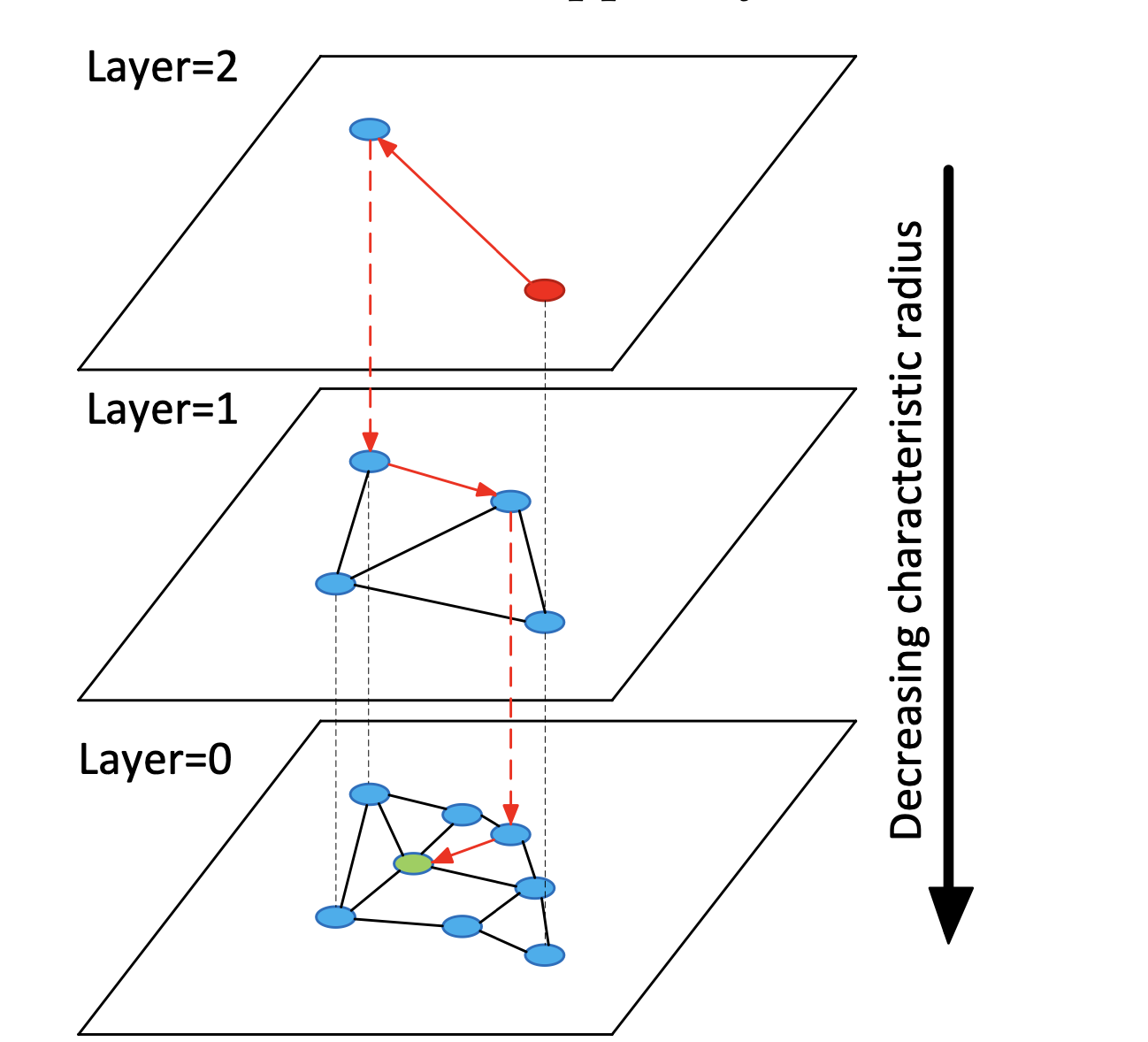
小世界图
小世界网络是一种特殊的图结构,它具有较短的平均路径长度和较高的聚类系数。在HNSW中,每一层都是一个小世界图。这种结构使得在图中的任意两点之间都存在一条相对较短的路径,大大提高了搜索效率。
近似搜索
与传统的KNN(K-Nearest Neighbors)算法不同,HNSW通过牺牲一小部分精度来换取显著的速度提升。它不保证一定能找到真正的最近邻,但可以以极高的概率找到足够接近的点,而且搜索速度要快得多。
3. HNSW的工作原理
数据结构:多层图的构建过程
- HNSW从底层开始构建,每个数据点都会出现在底层。
- 对于每个新插入的点,算法会随机决定它是否应该出现在上一层。这个过程一直持续到某一层,该点不再被选中。
- 在每一层,新点会与该层的其他点建立连接,形成小世界图结构。
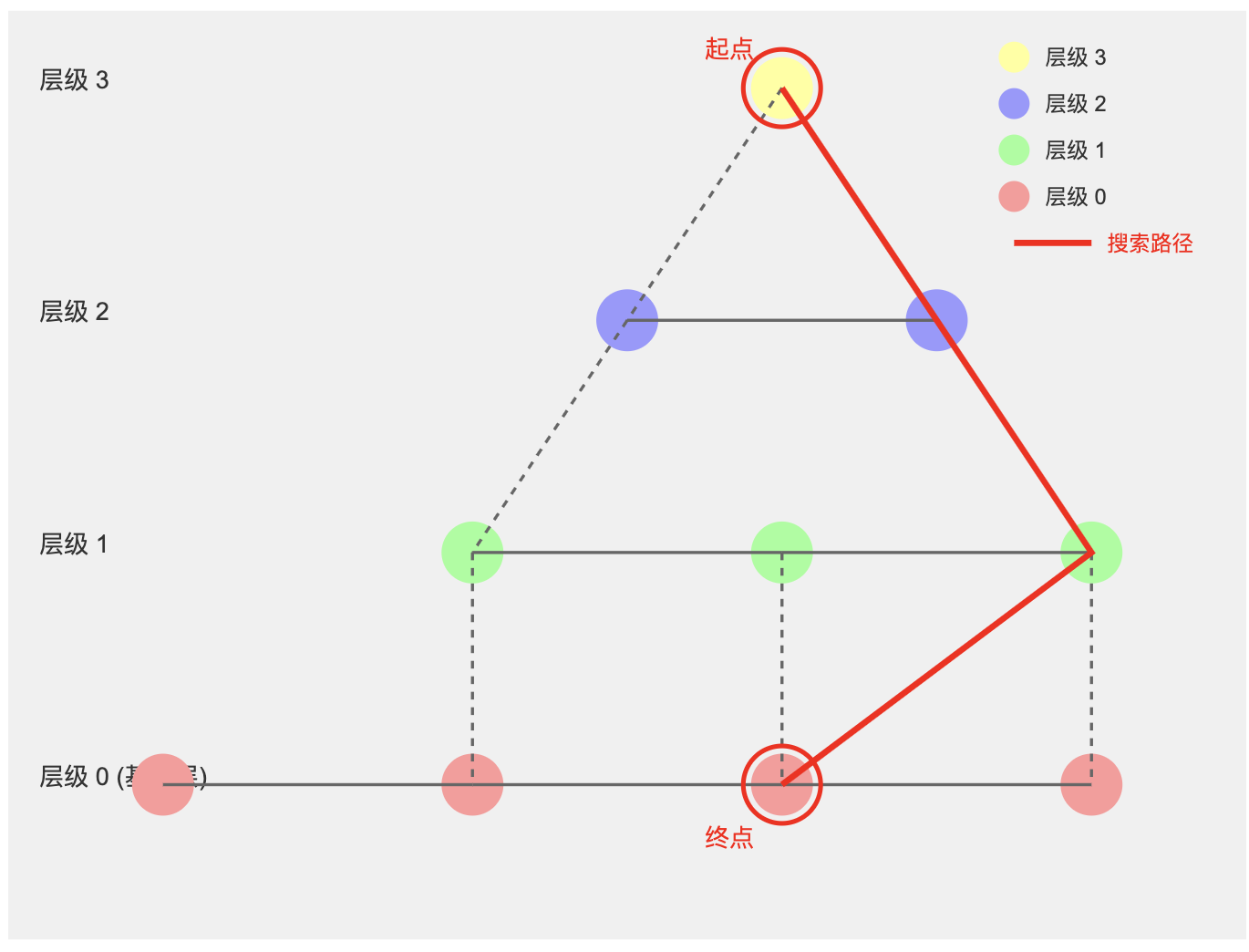
搜索过程:自顶向下的贪婪搜索
- 搜索从最顶层开始,选择一个随机起点。
- 在当前层进行贪婪搜索,不断移动到离目标更近的邻居。
- 当在当前层无法找到更近的点时,下降到下一层继续搜索。
- 重复这个过程直到达到底层,得到最终结果。
![]()
插入新向量的过程
- 确定新向量应该出现在哪些层。
- 从顶层开始,在每一层执行类似于搜索的过程,找到适合连接的邻居点。
- 建立连接,同时可能需要删除一些现有连接以维持图的结构特性。
![]()
论文中的算法是这样的![]()
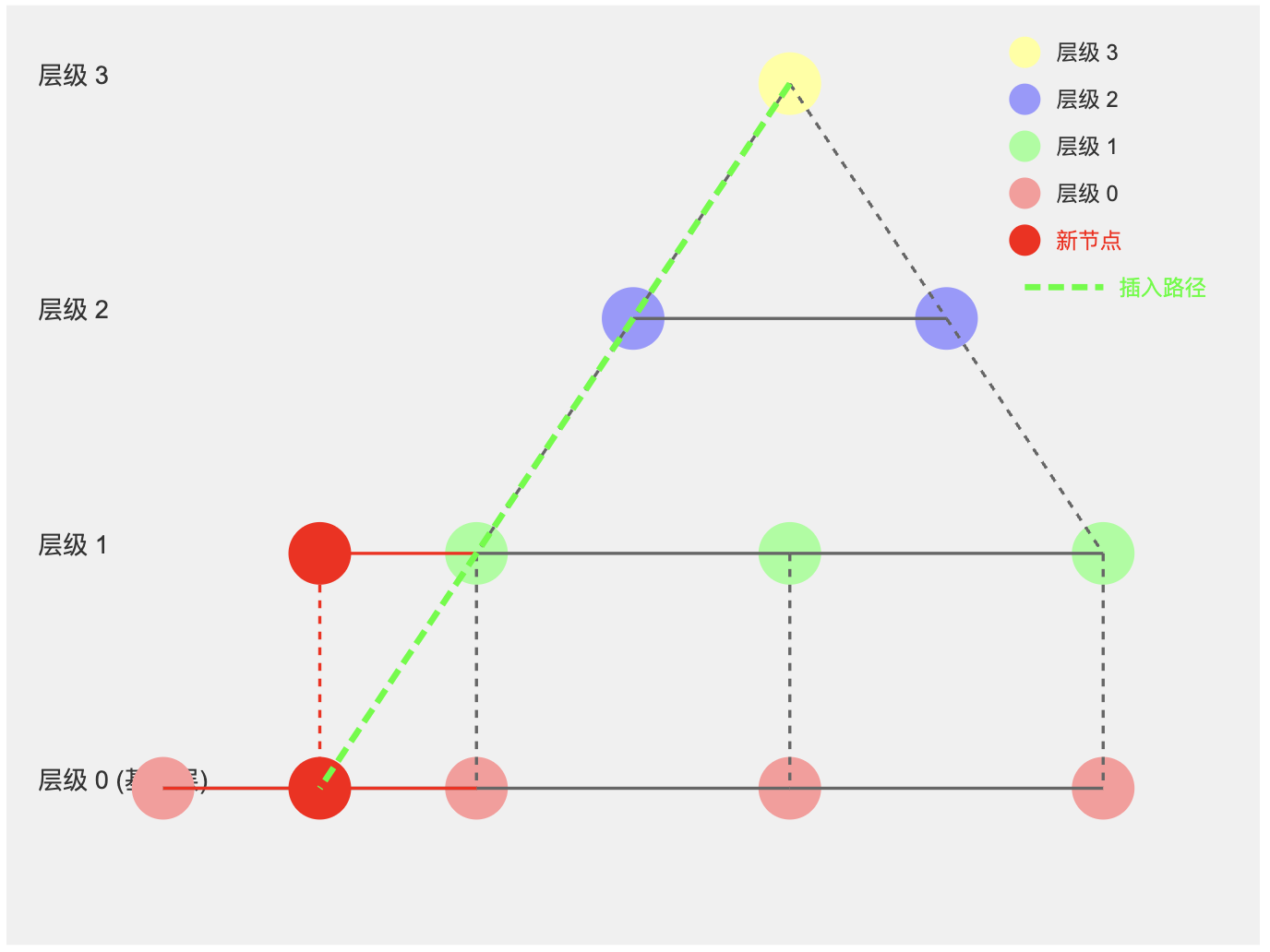

红色节点表示新插入的数据点。在这个例子中,新节点被插入到了层级0和层级1。
红色实线表示新建立的同层连接。新节点与其邻近节点建立了连接。
红色虚线表示新建立的跨层连接。新节点在不同层级之间建立了连接。
绿色虚线箭头表示插入过程的路径。这条路径展示了算法如何从顶层开始,逐层下降,最终确定新节点的插入位置。
其他颜色的节点和灰色的连接线表示原有的HNSW结构。
插入过程从顶层开始,沿着绿色虚线所示的路径向下搜索。
在每一层,算法都会寻找最近的邻居节点,并决定是否在该层插入新节点。
在本例中,新节点被插入到了层级0(基础层)和层级1。这是因为HNSW使用概率方法来决定节点应该出现在哪些层级。
插入后,新节点与其邻近节点建立连接(红色实线),以维持图的小世界特性。
同时,新节点也与其在不同层级的对应节点建立跨层连接(红色虚线),以确保层级之间的快速访问。
4. HNSW的性能分析
时间复杂度分析
- 搜索时间复杂度: O(log N),其中N是数据点的总数。
- 插入时间复杂度: 平均情况下为O(log N)。
空间复杂度分析
- 空间复杂度: O(N log N),因为上层节点数量呈指数衰减。
与其他ANN算法的比较
相比LSH(Locality-Sensitive Hashing)和Annoy等算法,HNSW在大多数场景下都能提供更好的查询性能和更高的准确率。然而,HNSW的内存消耗相对较高,这是它的一个潜在缺点。
5. HNSW的实际应用
在推荐系统中的应用
HNSW可以用于快速检索相似用户或物品,提高推荐系统的响应速度和准确性。例如,在音乐推荐中,可以用HNSW快速找到与用户喜好相似的歌曲。
在图像检索中的应用
在大规模图像数据库中,HNSW可以实现快速的相似图像搜索。这在图像搜索引擎、视觉商品搜索等场景中非常有用。
在自然语言处理中的应用
HNSW可以用于词嵌入或句子嵌入的快速检索,支持语义相似度计算、文本分类等任务。
6. HNSW的优化和变种
参数调优技巧
- 层数选择:影响搜索速度和内存使用
- 每层连接数:影响搜索准确度和构建时间
- 候选集大小:影响搜索质量和速度的平衡
常见的HNSW变种算法介绍
- NSW-G:改进了图的构建方法,提高了搜索效率
- HCNNG:结合了层次聚类,提高了在某些数据集上的性能
7. 实现HNSW的挑战与解决方案
大规模数据集的处理
- 使用外部存储和分批处理
- 采用压缩技术减少内存占用
并行化和分布式实现
- 搜索过程的并行化
- 分布式索引构建和查询
动态更新和删除操作的处理
- 软删除技术
- 定期重建索引
8. 总结与展望
HNSW算法通过其独特的分层小世界图结构,在保证高准确率的同时实现了对高维向量数据的快速检索。它在推荐系统、图像检索、自然语言处理等多个领域都有广泛应用。
未来,向量数据库技术可能会朝着以下方向发展:
- 更高效的压缩和索引技术
- 更好的动态更新支持
- 与深度学习模型的更紧密集成
- 针对特定领域的优化变体
随着人工智能和大数据技术的不断发展,HNSW等高效的向量检索算法将在更广阔的应用场景中发挥重要作用。