用 ollama 本地运行谷歌开源大模型 Gemma
原先在 23 年初的时候调研过一些国产的大模型,包括复旦开源的 MOSS 和清华的 ChatGLM,那时候还是早期版本,需要在 Linux 上,并且有比较好的显卡,而且一般来讲都得是 N 卡,过程中需要安装 pytorch和比较多依赖,并且当时的效果也还比较差,所以后面就没有长期使用。
最近看到谷歌在 2 月份开源了大模型 Gemma ,gemma 的博客在这里,想要在本地运行这个模型在现在这个阶段也变得简单很多,因为我们有了 ollama 工具
可以通过这个工具来运行大模型,并且已经支持了谷歌开源的 Gemma
我这边本地是 MacBook Pro 14 寸的,m3 pro 的处理器,18g 内存,刚好可以用 7b 量化的模型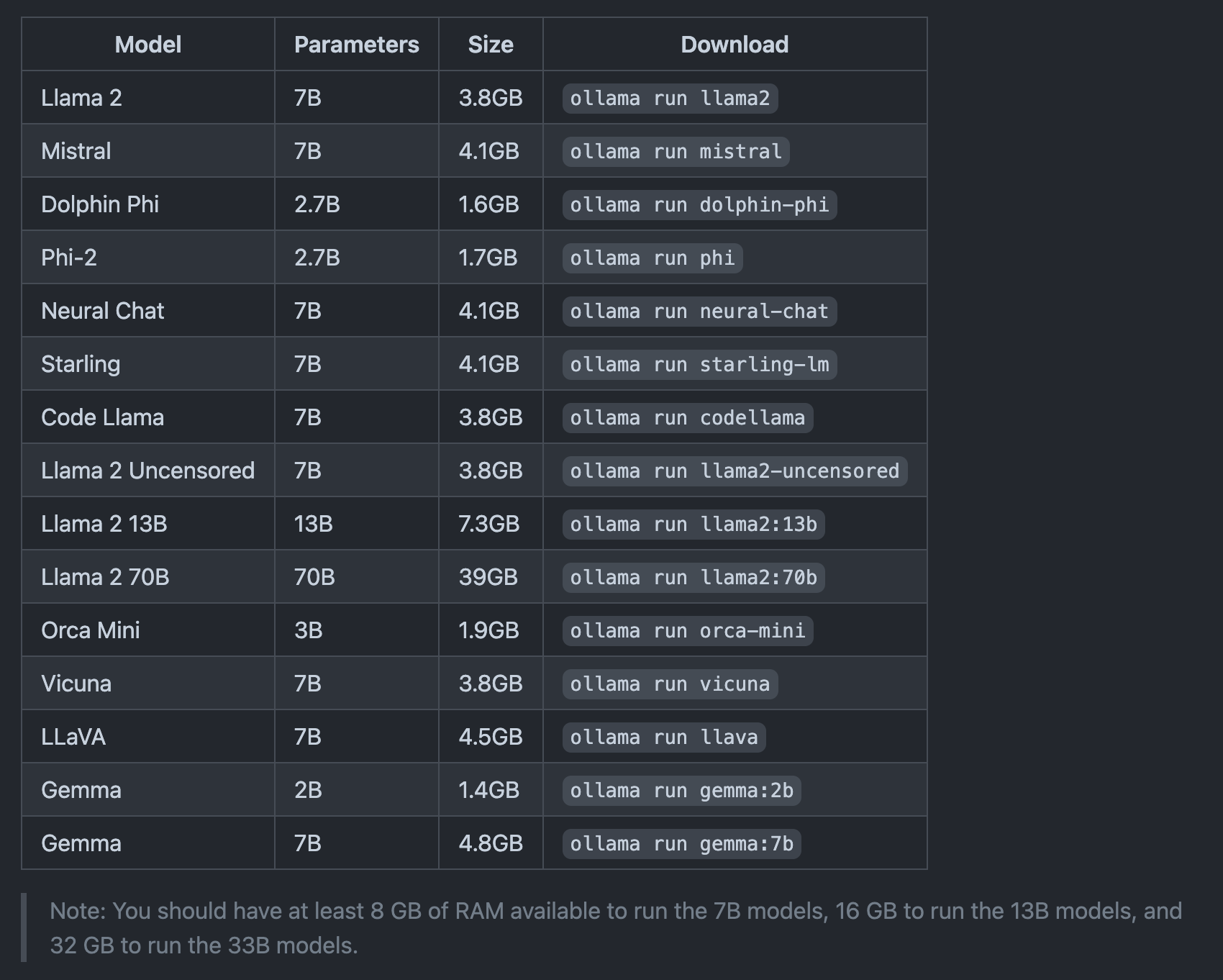
这里有推荐的模型和内存推荐匹配规则,16g 可以运行 13B 及以下模型
下载安装完后我们可以用以下命令1
ollama run gemma:7b
这里需要拉取模型,约5.2g 大小,考虑网络原因可能会比较慢
我们可以简单来试试问个问题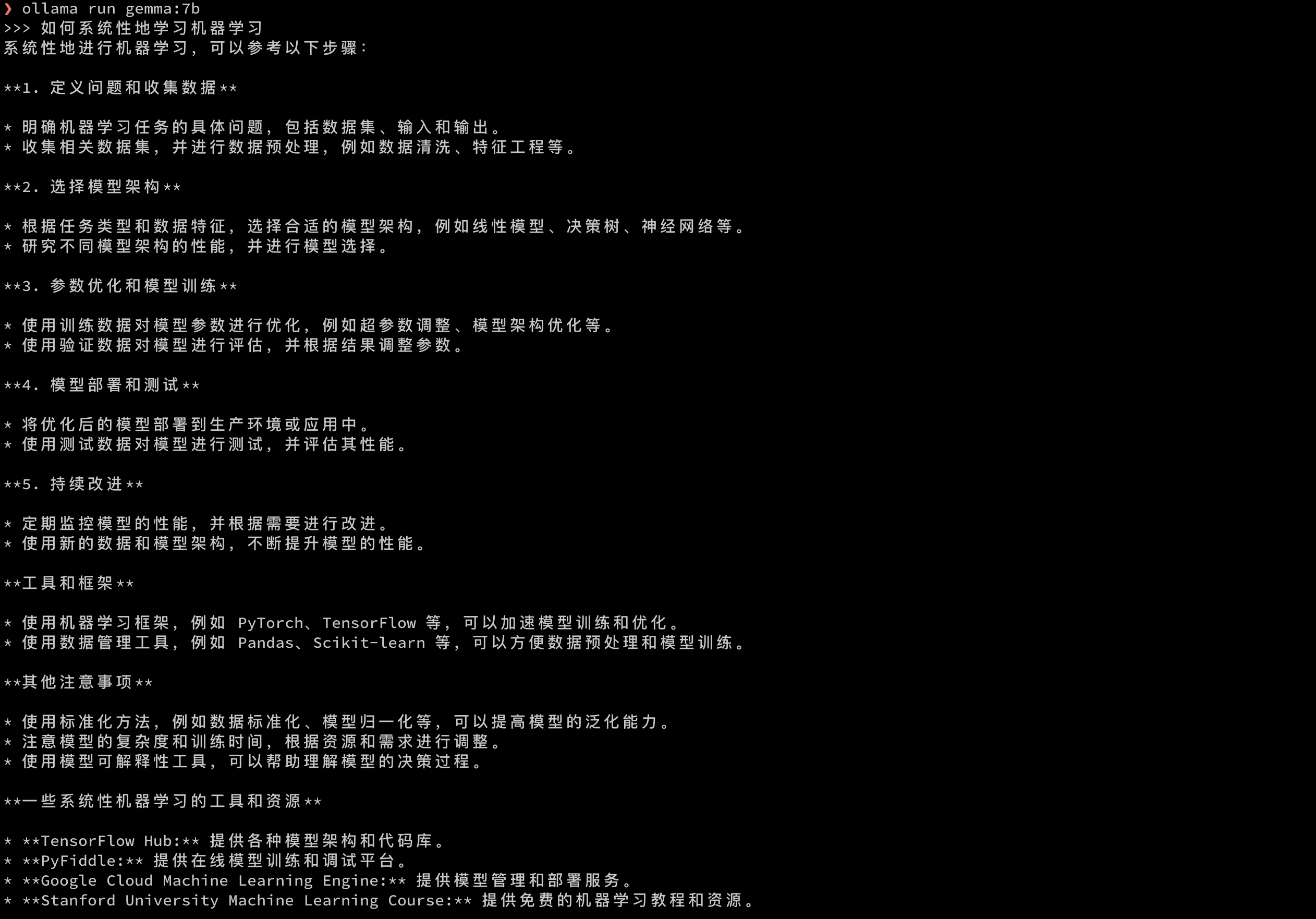
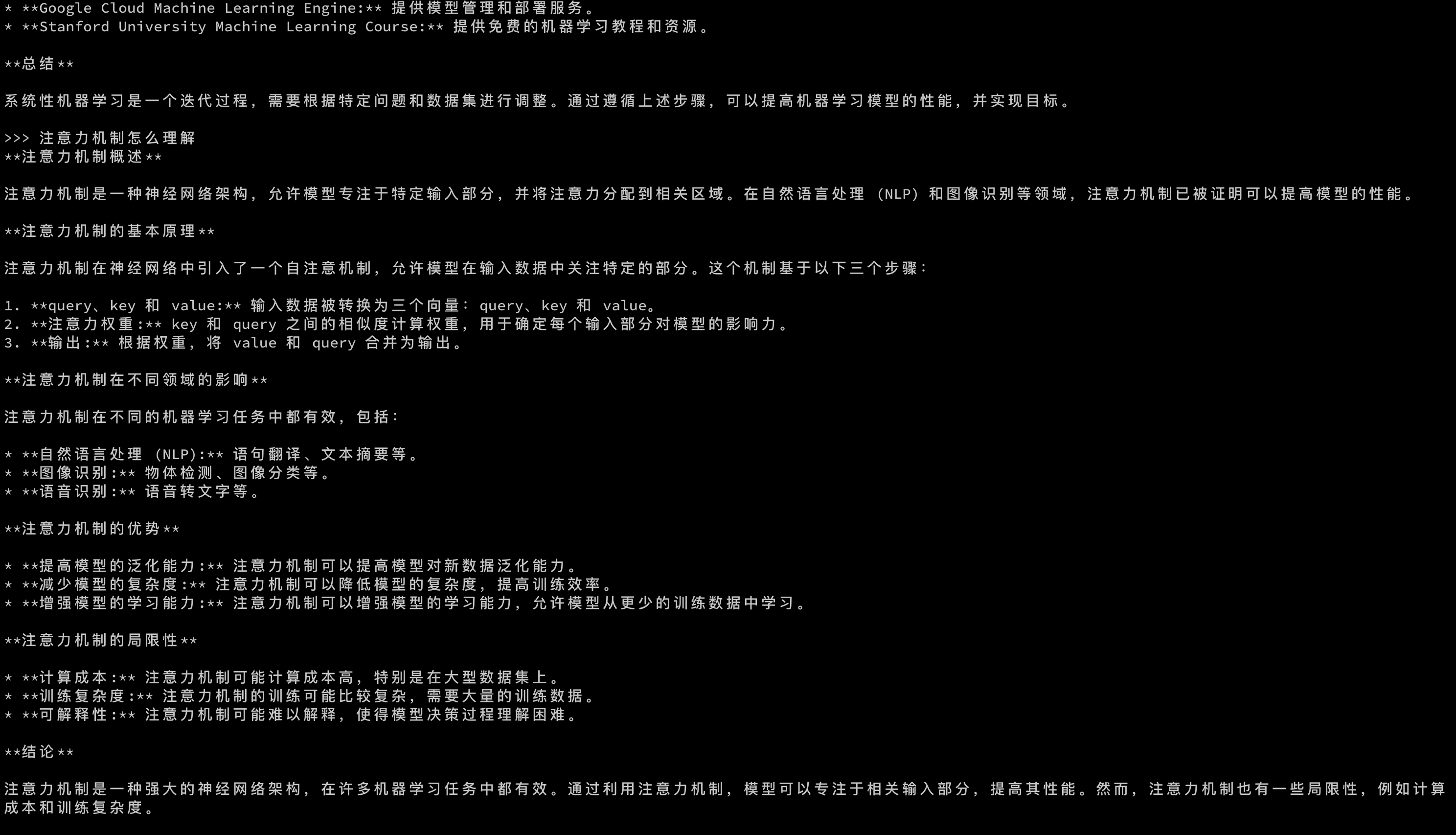
看出来回答的还是比较丰富的,谷歌出品还是比较有水平的,不至于像 ChatGLM 最初版本的在不做调优的情况下甚至有点前言不搭后语
对于想使用 chatgpt 但是没条件,这也算是个低配平替了, 并且已经是个比较可用的了,同时也方便进行学习调优等
如果想要类似于 chatgpt 那样的网页版,可以安装 open-webui
可以通过 webui 访问 ollama 运行的大模型,
用 docker 启动的命令也贴一下1
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
不过有个小问题就是 docker 镜像拉取会有点慢,可以添加下国内镜像加速1
2
3
4
5
6
7{
"registry-mirrors": [
"https://dockerproxy.com",
"https://docker.mirrors.ustc.edu.cn",
"https://docker.nju.edu.cn"
]
}
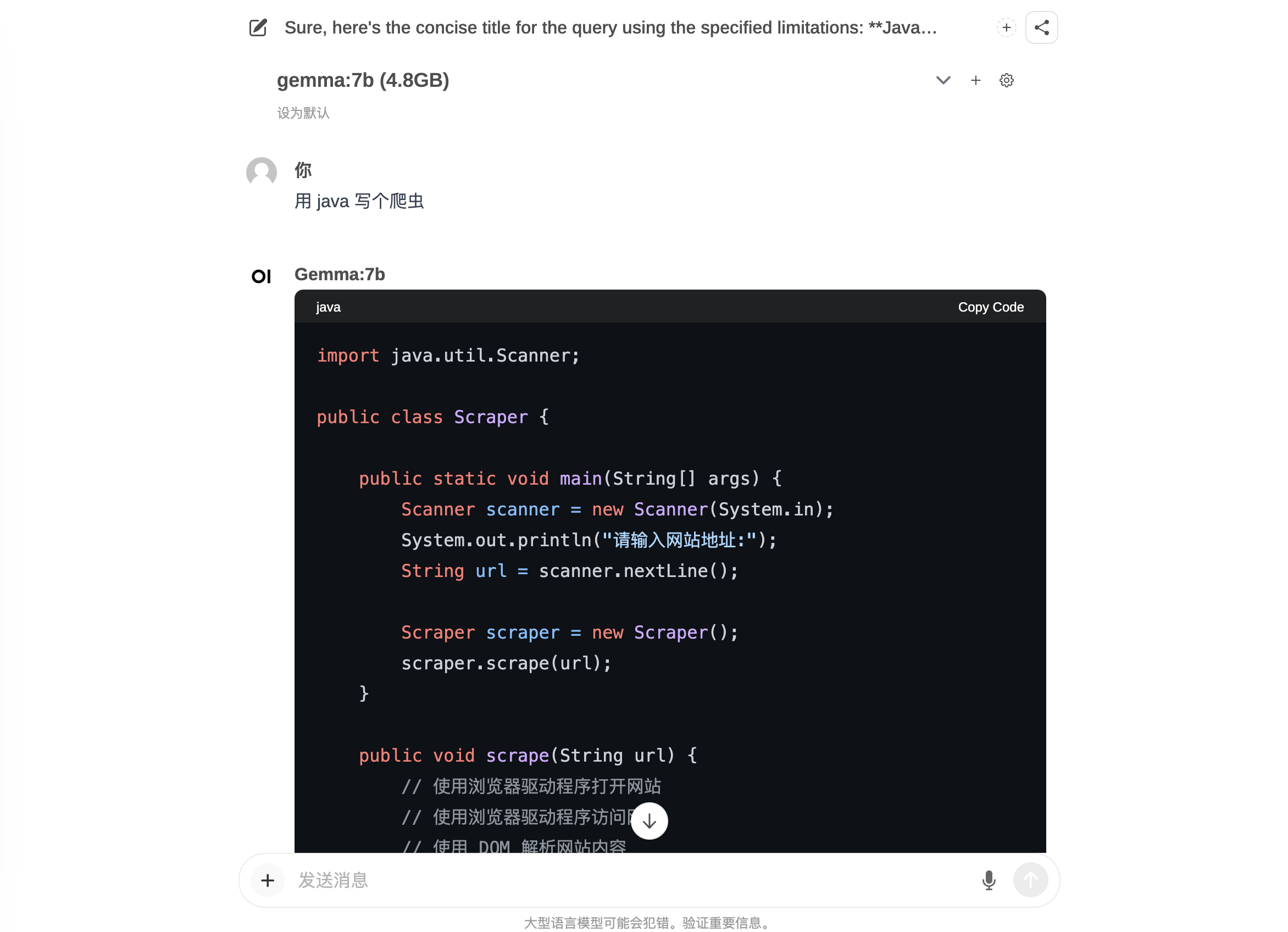
这里有一个小区别,Gemma 在多轮会话的时候会在前面的答案基础上再完善。
补充一个在 windows 环境下,cpu 跑模型的也是可行的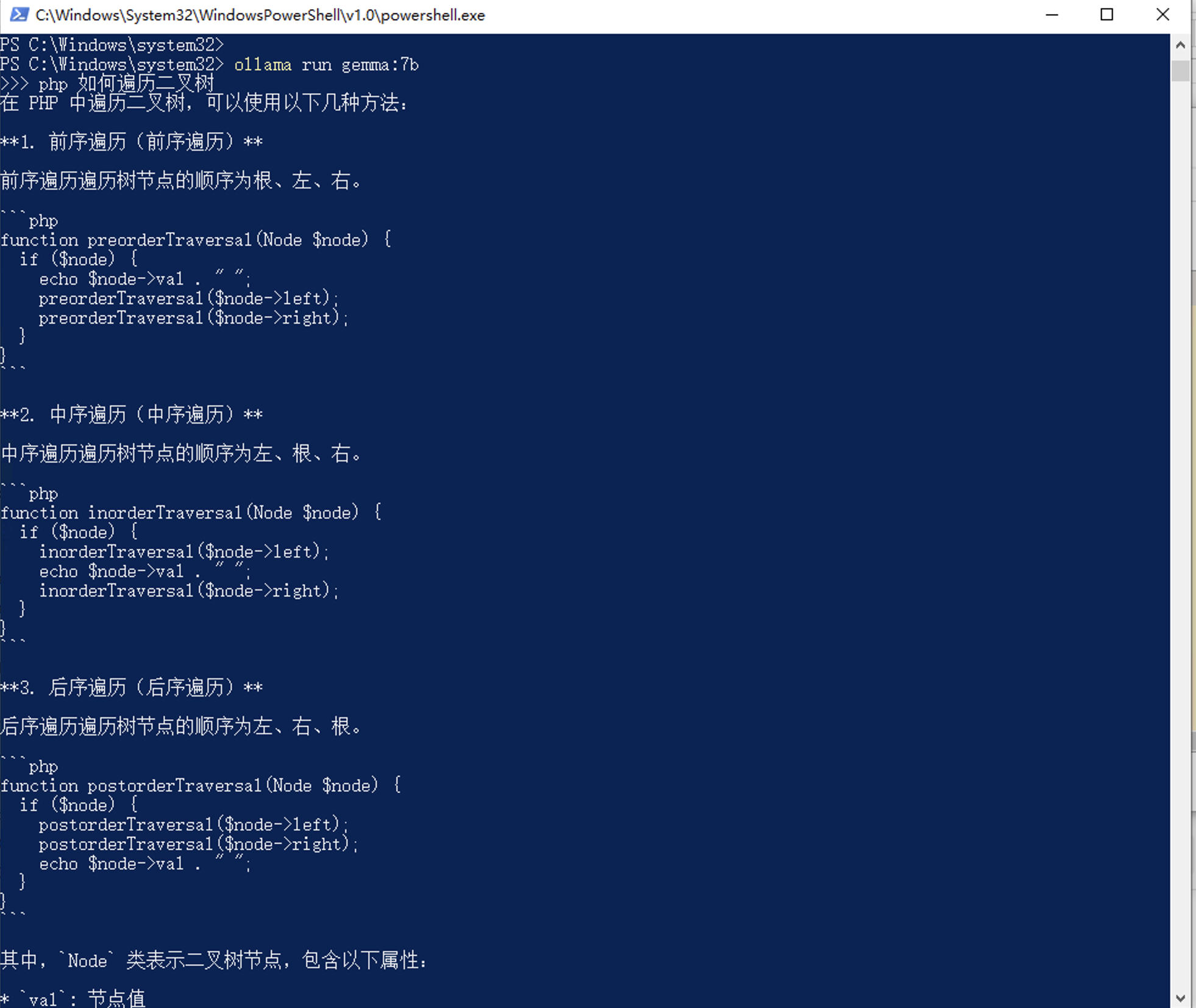
现在是大模型可以深入千家万户了,大家都可以尝试下,如果对日常的工作学习有一些效率上的提升也是好的