redis数据结构介绍-第一部分 SDS,链表,字典
redis是现在服务端很常用的缓存中间件,其实原来还有memcache之类的竞品,但是现在貌似 redis 快一统江湖,这里当然不是在吹,只是个人角度的一个感觉,不权威只是主观感觉。
redis 主要有五种数据结构,Strings,Lists,Sets,Hashes,Sorted Sets,这五种数据结构先简单介绍下,Strings类型的其实就是我们最常用的 key-value,实际开发中也会用的最多;Lists是列表,这个有些会用来做队列,因为 redis 目前常用的版本支持丰富的列表操作;还有是Sets集合,这个主要的特点就是集合中元素不重复,可以用在有这类需求的场景里;Hashes是叫散列,类似于 Python 中的字典结构;还有就是Sorted Sets这个是个有序集合;一眼看这些其实没啥特别的,除了最后这个有序集合,不过去了解背后的实现方式还是比较有意思的。
SDS 简单动态字符串
先从Strings开始说,了解过 C 语言的应该知道,C 语言中的字符串其实是个 char[] 字符数组,redis 也不例外,只是最开始的版本就对这个做了一丢丢的优化,而正是这一丢丢的优化,让这个 redis 的使用效率提升了数倍1
2
3
4
5
6
7
8struct sdshdr {
// 字符串长度
int len;
// 字符串空余字符数
int free;
// 字符串内容
char buf[];
};
这里引用了 redis 在 github 上最早的 2.2 版本的代码,代码路径是https://github.com/antirez/redis/blob/2.2/src/sds.h,可以看到这个结构体里只有仨元素,两个 int 型和一个 char 型数组,两个 int 型其实就是我说的优化,因为 C 语言本身的字符串数组,有两个问题,一个是要知道它实际已被占用的长度,需要去遍历这个数组,第二个就是比较容易踩坑的是遍历的时候要注意它有个以\0作为结尾的特点;通过上面的两个 int 型参数,一个是知道字符串目前的长度,一个是知道字符串还剩余多少位空间,这样子坐着两个操作从 O(N)简化到了O(1)了,还有第二个 free 还有个比较重要的作用就是能防止 C 字符串的溢出问题,在存储之前可以先判断 free 长度,如果长度不够就先扩容了,先介绍到这,这个系列可以写蛮多的,慢慢介绍吧
链表
链表是比较常见的数据结构了,但是因为 redis 是用 C 写的,所以在不依赖第三方库的情况下只能自己写一个了,redis 的链表是个有头的链表,而且是无环的,具体的结构我也找了 github 上最早版本的代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 值
void *value;
} listNode;
typedef struct list {
// 链表表头
listNode *head;
// 当前节点,也可以说是最后节点
listNode *tail;
// 节点复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值比较函数
int (*match)(void *ptr, void *key);
// 链表包含的节点数量
unsigned int len;
} list;
代码地址是这个https://github.com/antirez/redis/blob/2.2/src/adlist.h
可以看下节点是由listNode承载的,包括值和一个指向前节点跟一个指向后一节点的两个指针,然后值是 void 指针类型,所以可以承载不同类型的值
然后是 list结构用来承载一个链表,包含了表头,和表尾,复制函数,释放函数和比较函数,还有链表长度,因为包含了前两个节点,找到表尾节点跟表头都是 O(1)的时间复杂度,还有节点数量,其实这个跟 SDS 是同一个做法,就是空间换时间,这也是写代码里比较常见的做法,以此让一些高频的操作提速。
字典
字典也是个常用的数据结构,其实只是叫法不同,数据结构中叫 hash 散列,Java 中叫 Map,PHP 中是数组 array,Python 中也叫字典 dict,因为纯 C 语言本身不带这些数据结构,所以这也是个痛并快乐着的过程,享受 C 语言的高性能的同时也要接受它只提供了语言的基本功能的现实,各种轮子都需要自己造,redis 同样实现了自己的字典
下面来看看代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31typedef struct dictEntry {
void *key;
void *val;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
看了下这个 2.2 版本的代码跟最新版的其实也差的不是很多,所以还是照旧用老代码,可以看到上面四个结构体中,其实只有三个是存储数据用的,dictType 是用来放操作函数的,那么三个存放数据的结构体分别是干嘛的,这时候感觉需要一个图来说明比较好,稍等,我去画个图~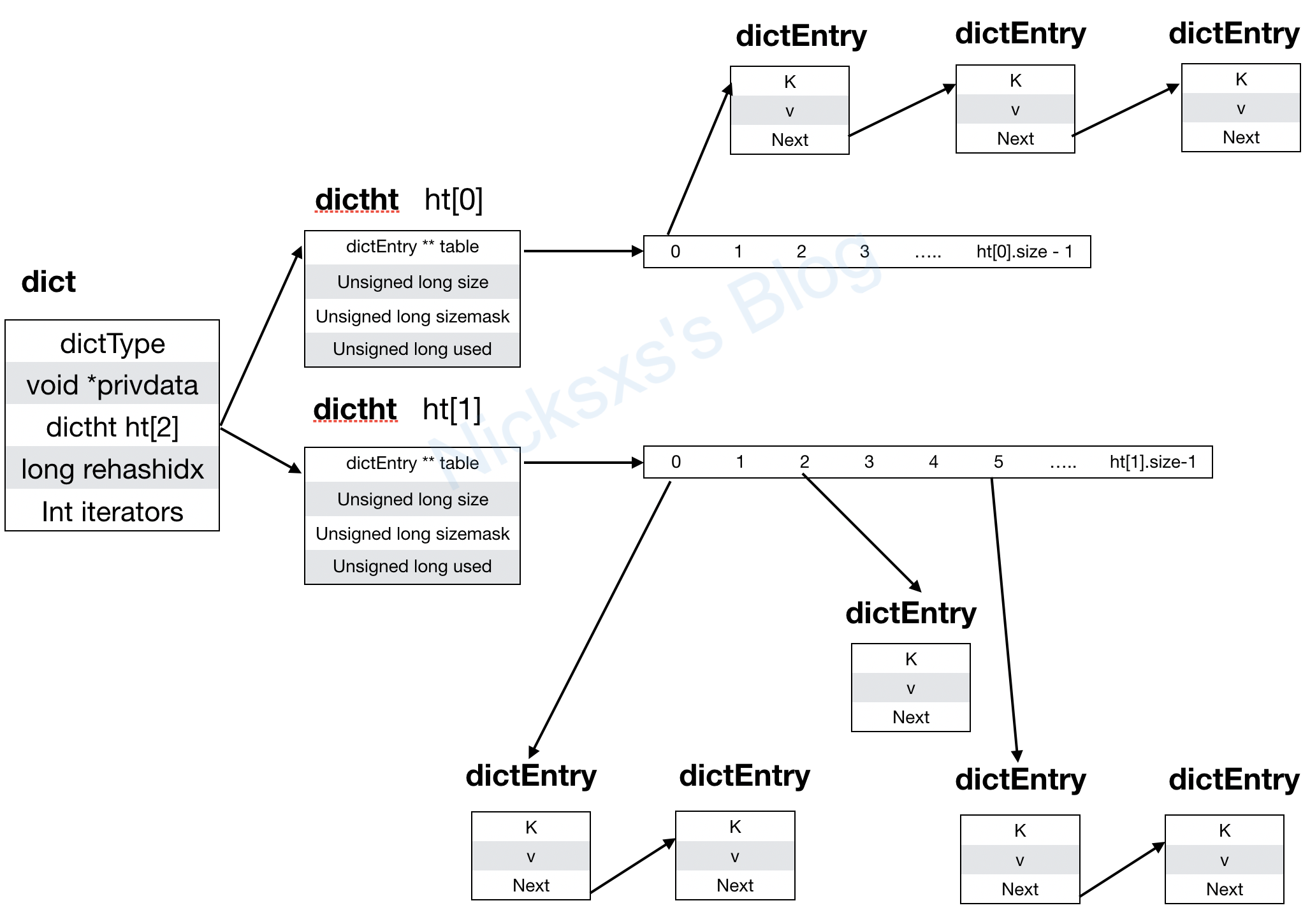
这个图看着应该比较清楚这些都是用来干嘛的了,dict 是我们的主体结构,它有一个指向 dictType 的指针,这里面包含了字典的操作函数,然后是一个私有数据指针,接下来是一个 dictht 的数组,包含两个dictht,这个就是用来存数据的了,然后是 rehashidx 表示重哈希的状态,当是-1 的时候表示当前没有重哈希,iterators 表示正在遍历的迭代器的数量。
首先说说为啥需要有两个 dictht,这是因为字典 dict 这个数据结构随着数据量的增减,会需要在中途做扩容或者缩容操作,如果只有一个的话,对它进行扩容缩容时会影响正常的访问和修改操作,或者说保证正常查询,修改的正确性会比较复杂,并且因为需要高效利用空间,不能一下子申请一个非常大的空间来存很少的数据。当 dict 中 dictht 中的数据量超过 size 的时候负载就超过了 1,就需要进行扩容,这里的其实跟 Java 中的 HashMap 比较类似,超过一定的负载之后进行扩容。这里为啥 size 会超过 1 呢,可能有部分不了解这类结构的同学会比较奇怪,其实就是上图中画的,在数据结构中对于散列的冲突有几类解决方法,比如转换成链表,二次散列,找下个空槽等,这里就使用了链表法,或者说拉链法。当一个新元素通过 hashFunction 得出的 key 跟 sizemask 取模之后的值相同了,那就将其放在原来的节点之前,变成链表挂在数组 dictht.table下面,放在原有节点前是考虑到可能会优先访问。
忘了说明下 dictht 跟 dictEntry 的关系了,dictht 就是个哈希表,它里面是个dictEntry 的二维数组,而 dictEntry 是个包含了 key-value 结构之外还有一个 next 指针,因此可以将哈希冲突的以链表的形式保存下来。
在重点说下重哈希,可能同样写 Java 的同学对这个比较有感觉,跟 HashMap 一样,会以 2 的 N 次方进行扩容,那么扩容的方法就会比较简单,每个键重哈希要不就在原来这个槽,要不就在原来的槽加原 dictht.size 的位置;然后是重头戏,具体是怎么做扩容呢,其实这里就把第二个 ht 用上了,其实这两个hashtable 的具体作用有点类似于 jvm 中的两个 survival 区,但是又不全一样,因为 redis 在扩容的时候是采用的渐进式地重哈希,什么叫渐进式的呢,就是它不是像 jvm 那种标记复制的模式直接将一个 eden 区和原来的 survival 区存活的对象复制到另一个 survival 区,而是在每一次添加,删除,查找或者更新操作时,都会额外的帮忙搬运一部分的原 dictht 中的数据,这里会根据 rehashidx 的值来判断,如果是-1 表示并没有在重哈希中,如果是 0 表示开始重哈希了,然后rehashidx 还会随着每次的帮忙搬运往上加,但全部被搬运完成后 rehashidx 又变回了-1,又可以扯到Java 中的 Concurrent HashMap, 他在扩容的时候也使用了类似的操作。